Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD

Level 2

Automatische vertaling
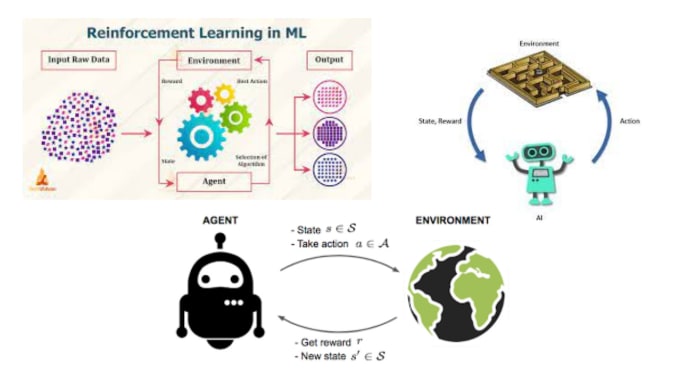
Policy Gradient Agents: Maak gebruik van de kracht van Policy Gradient-methoden, waarmee je AI-agenten leren om optimale policies te vinden via gradient ascent. Ik specialiseer me in het ontwerpen, trainen en finetunen van deze agents voor verschillende toepassingen.
Deep Deterministic Policy Gradient (DDPG): Profiteer van DDPG, een geavanceerd algoritme voor continue actie-ruimtes. Ik help je bij het implementeren en optimaliseren van DDPG-agents voor taken zoals robotica, controlesystemen en autonome voertuigen.
Proximal Policy Optimization (PPO): PPO staat bekend om zijn stabiliteit en robuustheid in RL. Ik begeleid je bij het gebruik van PPO om agents te trainen voor complexe omgevingen, met snelle convergentie en hoge prestaties.
Actor-Critic Architecturen: Gebruik Actor-Critic-methoden voor zowel discrete als continue actie-ruimtes. Profiteer van de synergie tussen waarde-functie benadering en policy-optimalisatie om uitdagende RL-problemen op te lossen.
Neural Network Integratie: Maak gebruik van de kracht van diepe neurale netwerken om de leervermogen van je RL-agents te verbeteren, zodat ze zich aanpassen en excelleren in complexe omgevingen.
optimized AI Models
Level 2
Talen
Automatische vertaling
