Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD
Wil je ruwe tekst, transcripties of enquêtegegevens omzetten in publicatieklare inzichten? Je bent op de juiste plek!
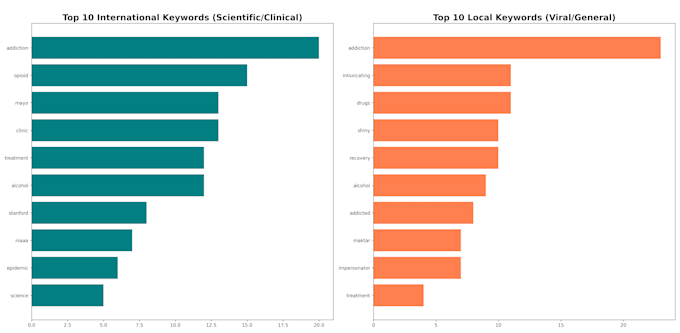
Als een Computational Data Analyst bouw ik robuuste Python Natural Language Processing (NLP) pipelines om verborgen linguïstische patronen en statistische inzichten uit ongestructureerde tekstgegevens te halen. Of het nu gaat om onderzoeksverhalen, volksgezondheidsgegevens of trends op sociale media, ik zorg voor maximale empirische waarde.
Wat deze dienst biedt:
Waarom ik? Gebaseerd op degelijke engineeringlogica, zodat je data mathematisch nauwkeurig en afgestemd is op top academische of presentatie-standaarden.
Stuur me een bericht met een beschrijving van je dataset voordat je bestelt!

Programmeertaal:
Python
Frameworks:
Scikit-learn
•
PyTorch
•
Panda
API's:
Google Cloud Vision API
Tools:
Overige
Automatische vertaling
Kan je NLP-pipeline meertalige of regionale tekstvertalingen aan?
Ja! Ik kan cross-linguïstische vertaallagen binnen de Python-pipeline implementeren voordat ik tekstuele analyse uitvoer. Zo worden lokale nuances nauwkeurig vastgelegd en gestructureerd zonder de native semantiek te verliezen.