Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD
Van rommelige data naar heldere inzichten met 37 jaar enterprise precisie
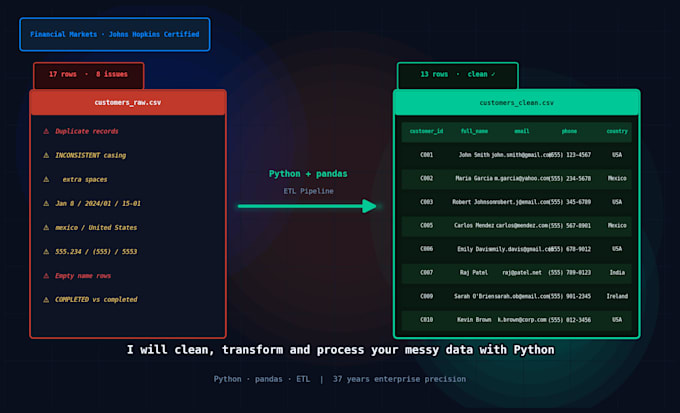
Is je data een rommel? Dubbele waarden, ontbrekende gegevens, inconsistente formaten?
Ik zet het snel om in schone, betrouwbare en direct te gebruiken datasets, met precisie op ondernemingsniveau.
Waarom vertrouwen op mij? Meer dan 37 jaar ervaring in IT en financiële markten. Leidde grootschalige data projecten bij een grote financiële instelling, waaronder instant payment systemen (FedNow-achtig) en GDPR/CCPA data governance programma's.
Wat ik schoonmaak:
Wat je ontvangt:
Heb je vragen? Stuur me een bericht voordat je bestelt. Ik kijk graag eerst een voorbeeld voor je na.
Laten we van je rommelige data je grootste troef maken.




Automatische vertaling
Met welke bestandsformaten werk je?
CSV, Excel (.xlsx/.xls), TXT en JSON. Als je een ander formaat hebt, vraag het gerust voordat je bestelt.
Kunt u overweg met grote datasets?
Ja. Ik heb datasets met miljoenen rijen verwerkt in productie-omgevingen in de financiële sector. Bestandsgrootte is geen probleem.
Ontvang ik de Python-script?
Ja, in het Premium (Enterprise Pipeline) pakket. Het script is volledig gecommentarieerd zodat jij en je team het altijd kunnen hergebruiken voor toekomstige datasets.
Wat als ik na de bevalling wijzigingen wil aanbrengen?
Kleine aanpassingen zijn inbegrepen in alle pakketten. Voor grotere wijzigingen kunnen we extra scope bespreken — geen verrassingen.