Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD
Bangladesh
Over mij
Wil je een zelf-gestuurd leren (SSL) model bouwen en betekenisvolle clusters in je data ontdekken?
- Je bent op de juiste plek! Ik ben een Deep Learning expert met praktische ervaring in SSL, clustering en evaluatie van downstream taken.
Ik kan werken met verschillende image datasets, waaronder:
Waarom kiezen voor mijn service?
Wat ik lever:
Laten we je data tot leven brengen! Stuur me een bericht voordat je bestelt om er zeker van te zijn dat je projectvereisten volledig begrepen worden.



Expertise:
Afbeeldingenverwerking
•
Classificatie
•
clustering
Programmeertaal:
Python
•
Colab
•
Overige
Tools:
Jupyter-notitieboek
•
opencv
•
Colab
•
PyTorch
Frameworks:
PyTorch
•
Panda
•
Overige
Automatische vertaling
Met welke soorten datasets kun je werken?
Ik kan werken met elk type image dataset, inclusief medische beelden, satellietbeelden, productafbeeldingen of persoonlijke/aangepaste datasets.
Moet ik een dataset aanleveren?
Ja. Als je het model wilt laten trainen op jouw data (producten, gezichten, documenten, etc.), moet je de afbeeldingen aanleveren. Als je geen dataset hebt, kan ik helpen er een te verzamelen of te vinden voor een extra vergoeding. Stuur me eerst een bericht!
Heb ik gelabelde data nodig?
Nee, zelf-gestuurd leren vereist geen gelabelde data. Labels kunnen nodig zijn als je evaluatie op een downstream taak wilt (Standaard & Premium pakketten).
Zijn er beperkingen qua datasetgrootte?
Ik werk meestal met datasets die in het beschikbare GPU-geheugen passen, bijvoorbeeld Colab en Kaggle GPU. Voor zeer grote datasets kunnen we strategieën gebruiken zoals sampling, batching of gedistribueerde verwerking.
Welke deep learning modellen gebruik je?
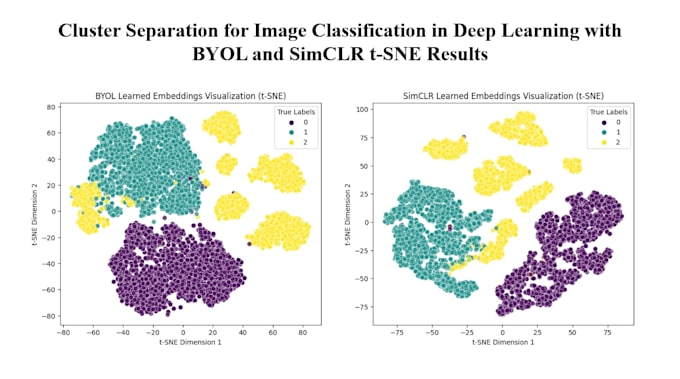
Ik gebruik state-of-the-art zelf-gestuurd leren (SSL) modellen zoals SimCLR, BYOL, Barlow Twins.
Zal ik het model makkelijk kunnen gebruiken?
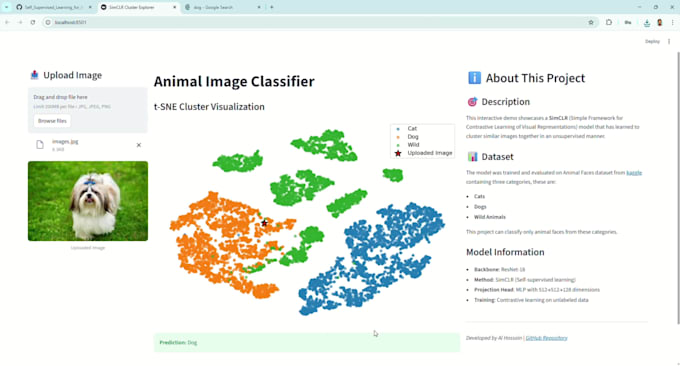
Ja! Voor het Premium pakket bied ik een gebruiksvriendelijke Streamlit web app om clusters interactief te verkennen en downstream taken te testen.
Kun je de prestaties van het model evalueren?
Ja, ik bied gedetailleerde evaluatiemetrics voor downstream taken, inclusief nauwkeurigheid, verlies en visualisaties van clusters.
Zorg je voor vertrouwelijkheid?
Ja, helemaal. Je data en projectgegevens blijven strikt vertrouwelijk.