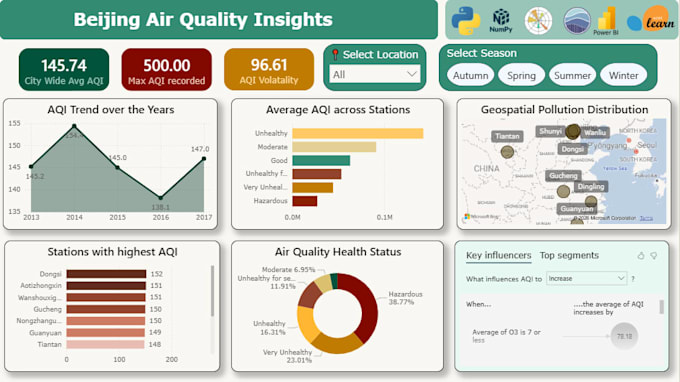
Heb je moeite met rommelige, inconsistente of "vuil" data?
Ruwe data is zelden klaar voor analyse. Of het nu gaat om ontbrekende waarden, inconsistente opmaak of verborgen uitschieters, ik ben hier om je chaotische datasets om te zetten in schone, bruikbare inzichten.
Diensten die ik aanbied:
- Data schoonmaken & pre-processing: Duplicaten verwijderen, ontbrekende data aanpakken en structurele fouten herstellen.
- EDA (Exploratory Data Analysis): Trends, correlaties en uitschieters identificeren.
- Data standaardisatie: Formaten converteren voor consistentie in je hele database.
- Geavanceerde visualisatie: Duidelijke, professionele grafieken maken.
- Voorspellende modellering: Als je data schoon is, kan ik een stap verder gaan en ML-modellen bouwen om je bedrijfsontwikkelingen te voorspellen.
De tech stack die ik gebruik:
- Talen: Python (Numpy, Pandas, Matplotlib, Seaborn, Scikit-learn, TextBlob)
- Databases: SQL
- Tools: Excel, Power BI, Plotly Express.
Wat je ontvangt:
- Een volledig schoongemaakte en geformatteerde dataset (.csv, .xlsx, of .sql).
- Een Python script/Jupyter Notebook (indien gevraagd) voor reproduceerbare resultaten.
- Een samenvatting waarin de aangebrachte veranderingen en gevonden inzichten worden uitgelegd.
Stuur me een bericht met een voorbeeld van je bestand, en laten we je project bespreken