Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD
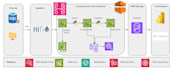
Data engineering, Azure, AWS, Databricks, Lakehouse, Spark, Fabric
Is je AWS data gescheiden, niet geoptimaliseerd of kost het je te veel?
Als Senior Data Engineer met 9 jaar ervaring bouw ik productieklare AWS ETL pipelines die geautomatiseerd, kostenefficiënt en schaalbaar zijn. Ik specialiseer me in het omzetten van gefragmenteerde S3 data in gestructureerde, high-performance assets voor analytics en AI.
Wat ik voor jou oplos:
Waarom kiezen voor deze dienst?
Ik schrijf niet alleen scripts; ik bouw architecturen. Elke pipeline die ik lever, is ontworpen om serverless te zijn, zodat je maandelijkse AWS-kosten minimaliseren en de throughput maximaliseren. Van S3 archiveringslogica tot geautomatiseerde waarschuwingen, ik zorg dat je data beheerd en betrouwbaar is.
Klaar om je AWS data stack te optimaliseren? Laten we een schaalbare pipeline bouwen


Automatische vertaling
Welke AWS-diensten gebruik je voor ETL-pijplijnen?
Ik gebruik AWS Glue, S3, Redshift, IAM, CloudWatch en Spark, afhankelijk van de projectbehoeften.
Kun je zowel batch- als incrementele pijplijnen bouwen?
Ja, ik ontwerp zowel batch- als incrementele pijplijnen op basis van datavolume en latency-eisen.
Behandel je datakwaliteitsvalidatie?
Ja, ik implementeer validatiecontroles, schema-afdwinging en anomaliedetectie.
Kun je bestaande AWS-pijplijnen optimaliseren?
Absoluut. Ik optimaliseer prestaties, kosten en betrouwbaarheid.
Lever je documentatie aan?
Ja, volledige technische documentatie en overdracht.
Ondersteun je API-data-inname?
Ja, REST API's, databases en bestandsbronnen.
Kun je CI/CD-pijplijnen bouwen?
Ja, op aanvraag.
Wordt beveiliging geregeld?
Ja, IAM-rollen, encryptie en toegangscontroles.
Ondersteun je real-time pijplijnen?
Ja, met Kafka / Kinesis indien nodig.
Bieden jullie ondersteuning na de bevalling?
Ja, ik bied ondersteuning na de bevalling.


