Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD
Webontwikkelaar
Ben je op zoek naar Mexicaanse Spaanse AI-training en NLP-expertise?
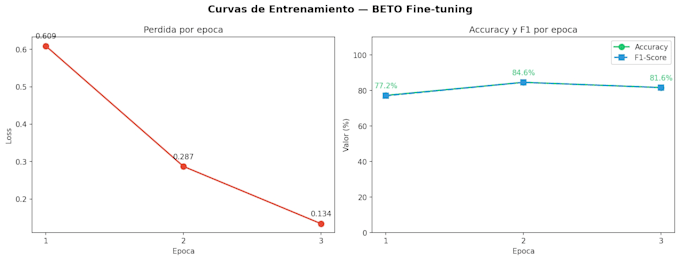
Ik specialiseer me in Natural Language Processing met praktische ervaring in het trainen van echte modellen. Ik heb Fake Radar gebouwd, een Spaans systeem voor het detecteren van nepnieuws met een fijn afgesteld BERT-model dat is getraind op 676 nieuwsartikelen met PyTorch en HuggingFace Transformers.
Wat ik aanbied:
Waarom Mexicaans Spaans belangrijk is: Regionale taal bevat unieke uitdrukkingen, idiomen en contexten die door generieke Spaanse modellen worden gemist. Ik breng native linguïstische kennis samen met technische ML-vaardigheden.
Klaar om je Spaanse AI-model te verbeteren? Stuur me een bericht voordat je bestelt en laten we je project bespreken.


Automatische vertaling
Moet ik een dataset aanleveren?
Niet per se. Ik kan werken met je bestaande data of je helpen bepalen welke data nodig is voor jouw specifieke NLP-geval.
Wat maakt Mexicaans Spaans anders dan andere Spaanse dialecten?
Mexicaans Spaans heeft unieke idiomen, colloquialismen en culturele verwijzingen die door generieke Spaanse modellen vaak verkeerd worden geïnterpreteerd. Native expertise zorgt ervoor dat je model de echte wereld begrijpt.
Geef je de broncode door?
Ja, broncode is inbegrepen bij alle pakketten zodat je volledige eigendom hebt over het geleverde werk.