Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD
Pakistan
3 bestellingen voltooid
AWS, Data Engineer, LangChain, FASTApi, Django Data Analist, ML
Ik bied een dienst aan die gericht is op het extraheren van gegevens uit verschillende bronnen en het uitvoeren van sentimentanalyse voor tekstclassificatie. Met mijn expertise in natural language processing (NLP) en machine learning kan ik je helpen waardevolle inzichten uit tekstuele data te halen en deze te classificeren op basis van sentiment.
Dit is wat mijn dienst omvat:
Technologie:
Python
Automatische vertaling
Q1: Van welke soorten databronnen kun je informatie extraheren?
Ik kan gegevens ophalen uit verschillende bronnen zoals websites, social media platforms (Twitter, Facebook, etc.), online forums, APIs, databases en meer. Laat me weten welke specifieke bronnen je interesse hebben, en ik werk met je samen om de data te verkrijgen.
Q2: Hoe zorg je voor de nauwkeurigheid van de sentimentanalyse?
Ik gebruik gevestigde NLP-technieken en machine learning algoritmes om sentimentanalyse uit te voeren. Om de nauwkeurigheid te waarborgen, train en finetune ik modellen op gelabelde data en voer ik strenge validatie en evaluatie uit. Het is echter belangrijk te realiseren dat sentimentanalyse beperkingen kan hebben, vooral bij complexe teksten.
Kun je grote hoeveelheden data verwerken voor analyse?
Ja, ik kan grote hoeveelheden data verwerken voor analyse. De verwerkingstijd kan variëren afhankelijk van de omvang van de dataset en de complexiteit van de analyse. We kunnen je specifieke datawensen bespreken, en ik optimaliseer de workflow om de data efficiënt te verwerken.
Kun je de categorieën voor tekstclassificatie aanpassen aan mijn specifieke behoeften?
Absoluut! Ik pas de categorieën voor tekstclassificatie aan op basis van jouw wensen. We bespreken de gewenste klassen of categorieën waarin je de tekst wilt indelen, en ik stem de analyse daarop af.
Moet ik gelabelde data aanleveren voor sentimentanalyse of tekstclassificatie?
Gelabelde data is nuttig voor het trainen van machine learning modellen voor sentimentanalyse of tekstclassificatie. Als je al gelabelde data hebt, kan dat de nauwkeurigheid van de modellen aanzienlijk verbeteren. Als je geen gelabelde data hebt, kunnen we andere opties bespreken zoals het gebruik van pre-trained modellen.
Welke visualisaties en rapporten ontvang ik?
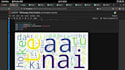
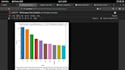
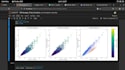
Ik kan visualisaties leveren zoals grafieken, diagrammen, word clouds of sentimentverdelingen om je te helpen de resultaten van de sentimentanalyse of tekstclassificatie te begrijpen. Daarnaast kan ik rapporten genereren die de bevindingen en inzichten uit de analyse samenvatten.


