Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD





Automatische vertaling
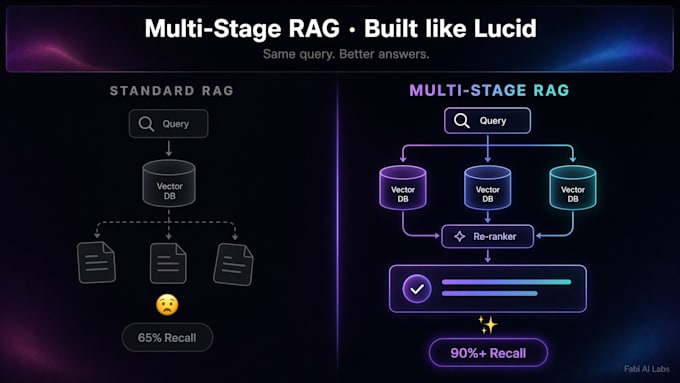
Standaard RAG loopt vast bij samengestelde vragen. Een enkele-query bot haalt stukjes op met "refund" en mist nuance - prijsregels, schadeclausules, maatwerkbeleid.
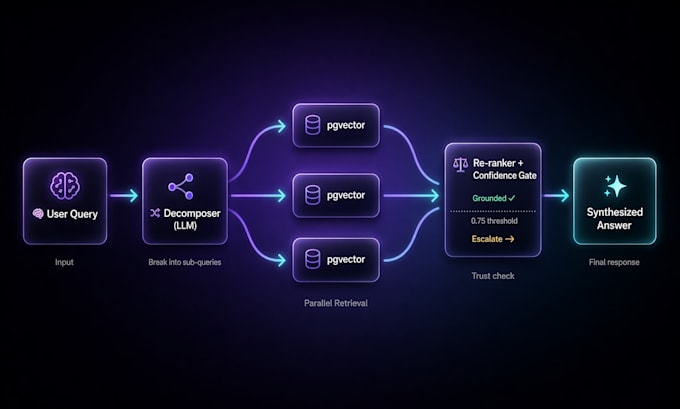
Multi-stage RAG is anders. Het decomprimeert in sub-queries, haalt parallel op, herordent en syntheseert. Het recall percentage stijgt van 65% naar 90%+. Antwoorden blijven onderbouwd. Hallucinaties dalen.
WAT JE KRIJGT:
- Query-decompositie (LLM splitst samengestelde vragen in gerichte zoekopdrachten)
- HyDE hypothetisch document-embedding voor retrieval
- Herordening + confidence scoring vóór antwoordgeneratie
- 4 safeguards: menselijke overdracht, onzekerheidsdeur, geen gaslighting, transparantie
- Aangepaste eval-testset met meetbare retrieval-kwaliteit
- Beheerdersdashboard voor conversatie- en retrieval-debugging (Premium)
STACK: Python/TypeScript, Supabase pgvector, OpenAI/Anthropic/Gemini APIs, aangepaste re-ranker.
WAAROM MULTI-STAGE: single-query RAG werkt voor eenvoudige FAQ's. Als je bot prijsnuance of samengestelde vragen behandelt - heb je dit nodig.
Dit is wat ik in Lucid heb gebouwd. Zelfde architectuur voor jouw domein, afgestemd op jouw stem.
Stuur me je use case plus 10 moeilijke vragen die je huidige bot niet kan beantwoorden. Ik reageer met de scope.
AI Developer and Creator of Lucid
Talen
Automatische vertaling
Automatische vertaling
Hoe verschilt multi-stage RAG van basic RAG?
Basic RAG voert één vector search uit per vraag. Bij samengestelde vragen is het recall percentage ongeveer 65%. Multi-stage RAG decomprimeert de vraag, zoekt parallel, herordent. Het recall percentage stijgt naar 90%+. Minder hallucinaties, beter onderbouwde antwoorden.
Kost dit meer dan basic RAG op grote schaal?
Vaak minder. Decompositie gebruikt goedkope modellen (Gemini Flash voor ongeveer $0,10 per 1M tokens). Het uiteindelijke antwoord gebruikt één premium modelcall. Basic RAG betaalt premium voor elke call. Bij meer dan 10k gesprekken per maand, draait multi-stage vaak 30-50% goedkoper.
Wat als mijn documenten rommelig of ongestructureerd zijn?
Wordt als onderdeel van de scope behandeld. Ik normaliseer documenten tijdens ingestie - chunking op basis van semantische grenzen (niet naïeve paragraaf splitsingen), schoonmaken van boilerplate, metadata toevoegen voor filtergebaseerde retrieval. Rommelige input is de standaardaanname, geen uitzondering.
Neem ik nog steeds mijn eigen API-sleutels mee?
Ja - dezelfde policy als mijn Starter Bot gig. Jij bezit de OpenAI / Anthropic / Gemini accounts, betaalt rechtstreeks zonder markup, behoudt volledige controle. Ik help je de meest kostenefficiënte modelmix te kiezen voor jouw verkeer.