Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD


Automatische vertaling
Stop met geld verbranden aan overbodige AI-aanroepen!
De meeste AI-apps verspillen 40% tot 80% van hun budget aan overbodige LLM-aanroepen. Ik ben hier om je te helpen stoppen met het verlies.
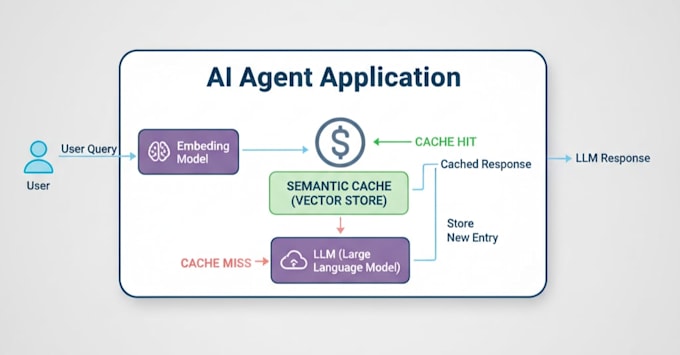
Ik bouw een Productieklaar Semantisch Cache dat "herinnert" wat eerdere queries waren en direct antwoorden geeft, waardoor je kosten dalen en je app supersnel aanvoelt.
Wat is Semantische Caching?
Standaard caching is "dom" en vereist een 100% woord-voor-woord match. Semantische caching is slim. Met behulp van Vector Embeddings begrijpt je systeem bedoeling. Als Gebruiker A vraagt "Hoe is het weer?" en Gebruiker B vraagt "Wat is de weersvoorspelling?", weet het systeem dat ze hetzelfde zijn. Het serveert het opgeslagen antwoord direct zonder je API te gebruiken.
️ Wat zit er in deze dienst?
Code, Scrape, Automate, FullStack Developer for Data and AI
Talen
Automatische vertaling
Automatische vertaling
Zorgt caching er niet voor dat de AI "oude" of "verkeerde" informatie geeft?
Niet als het goed wordt gedaan. We implementeren "Cache Invalidation" en "Time-to-Live" (TTL) instellingen. Als je data vaak verandert, kunnen we de cache elke uur laten verlopen. Als het statische data is, kan het voor altijd blijven. We stemmen ook de "Similariteit Drempel" af zodat alleen echt vergelijkbare vragen een cache triggeren.</p>
Hoeveel geld bespaar ik echt?
Dit hangt af van je "Cache Hit Rate." Voor klantenservice-bots of FAQ's vragen gebruikers vaak vergelijkbare vragen, wat 60-90% besparingen oplevert. Voor zeer creatieve of unieke taakbots ligt de besparing meestal rond de 20-30%.
Zijn mijn gegevens veilig?
Helemaal. De cache wordt gehost op jouw infrastructuur (of jouw favoriete cloud-database). Ik sla je data niet op mijn eigen servers op.
Werkt dit met elke LLM?
Ja. Of je nu OpenAI’s GPT-4o gebruikt, Google Gemini 1.5, Claude 3.5, of zelfs lokale modellen zoals Llama 3, de cachinglaag zit voor de API en maakt het provider-agnostic.