Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD
Ontwikkelaar van digitale producten
Ben je op zoek naar een professionele Data Scientist of Machine Learning Engineer? Ik ontwikkel op maat gemaakte AI-oplossingen die resultaten opleveren. Met een achtergrond in Computer Science en Full-Stack Development bied ik end-to-end integratie, van het trainen van modellen tot het bouwen van functionele webinterfaces.
Mijn diensten:
Tools & stack:
Waarom mij inhuren?
Neem contact met mij op voordat je bestelt om je specifieke wensen te bespreken!


Programmeertaal:
Python
•
R
•
SQL
Frameworks:
Scikit-learn
•
SimpleCV
•
keras
•
PyTorch
•
Panda
Tools:
Jupyter-notitieboek
•
opencv
•
tensorflow
•
Excel
•
Colab
Automatische vertaling
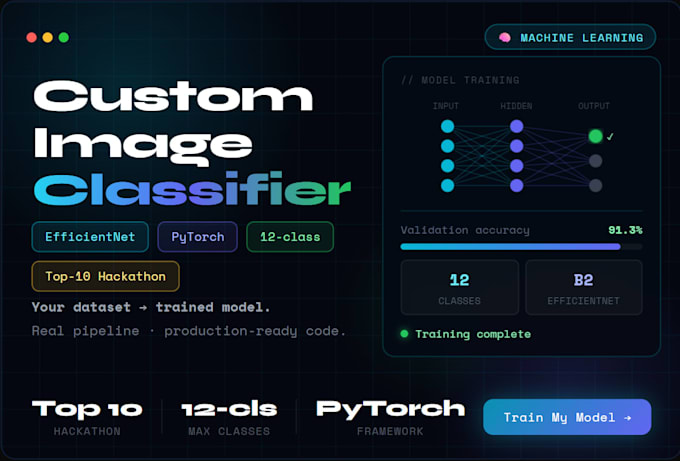
Welke soorten beelden kan je classificeren?
Vrijwel elk domein — medische beelden (huidlaesies, röntgenfoto's), productfoto's, wildlife, documenten, satellietbeelden en meer. Als je een dataset en een labelingschema hebt, kan ik er een model voor bouwen.
Hoeveel klassen kan jouw model aan?
Ik heb gewerkt met classificatieproblemen tot 12 klassen in productieomgevingen. Ik kan omgaan met binaire tot multi-class setups (20+ klassen), afhankelijk van de grootte en complexiteit van jouw dataset.
Welke frameworks en architecturen gebruik je?
PyTorch is mijn belangrijkste framework. Ik werk met bewezen architecturen zoals EfficientNet, ResNet en ViT, en kies de beste op basis van jouw datagrootte en nauwkeurigheidseisen.
Wat moet ik aanleveren?
Jouw gelabelde image dataset (georganiseerd in mapjes per klasse of met een CSV-labelbestand), het aantal doelklassen, en eventuele specifieke nauwkeurigheids- of deployment-eisen die je hebt.
Wat als mijn dataset klein is?
Kleine datasets worden behandeld met transfer learning van voorgetrainde modellen, gecombineerd met augmentatiestrategieën (flips, rotaties, kleurverandering en geavanceerde technieken zoals CutMix/MixUp) om de generalisatie te maximaliseren.
Wat ontvang ik als resultaat?
Een getraind modelbestand (.pt / .onnx), een schoon inference-script, een trainingsrapport met nauwkeurigheid/verlies-curves en per-klasse metrics, en instructies over hoe je voorspellingen kunt doen op nieuwe beelden.
Onderteken je NDA's of houd je mijn gegevens vertrouwelijk?
Ja. Jouw dataset en zakelijke context blijven privé. Ik onderteken graag een NDA indien nodig voordat je data deelt.