Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD
Senior Laravel architect en AI automation specialist
De uitdaging:
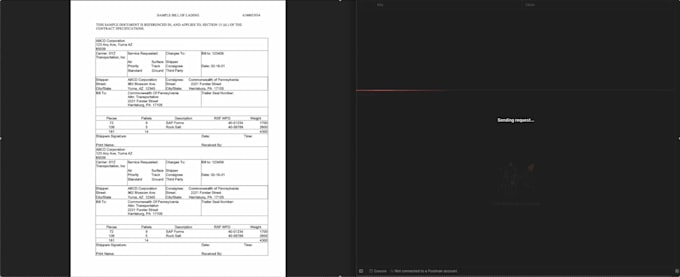
De "Onleesbare" Document Standaard OCR-automatisering faalt vaak bij scheve scans en lage-resolutie PDFs. De meeste diensten vereisen starre sjablonen die breken zodra een verzender hun formulier bijwerkt.
De oplossing:
Professionele AI-gebaseerde parsing. Deze dienst biedt een gespecialiseerde data-extractieservice die je fysieke of digitale documenten omzet in georganiseerde JSON-bestanden.
Gebruikte tools:
Wat deze dienst biedt:
OPMERKING: Voor multipage PDFs wordt één pagina als één document beschouwd en documenten moeten geprint zijn NIET HANDGESCHREVEN.
Klaar om je data op te schonen? Laten we



Technologie:
Python
Type informatie:
Overige
Techniek:
Geautomatiseerd
Automatische vertaling
Moet ik een sjabloon aanleveren voor mijn facturen of BoLs?
Nee. Mijn engine is lay-out-agnostisch. Of je nu verschillende vervoerders hebt en verschillende factuurstijlen, het systeem identificeert de belangrijke velden (door jou aangeleverd) zonder dat je voor elk een vooraf gedefinieerd sjabloon nodig hebt.
Wat gebeurt er als een document extreem wazig of onleesbaar is?
Ik gebruik geavanceerde beeldoptimalisatietechnieken om schuddende of slecht verlichte scans te verduidelijken. Als een document echter fysiek ontbreekt of volledig onleesbaar is, zelfs voor het menselijk oog, markeer ik dat specifieke bestand en informeer ik je, in plaats van "geraden" of hallucinatiegegevens te geven.
Zijn mijn gegevens veilig?
Absoluut. Gegevensprivacy is een prioriteit. Ik verwerk je documenten uitsluitend voor de extractie. Zodra de geverifieerde JSON-bestanden zijn geleverd en je de ontvangst hebt bevestigd, kan ik alle bronafbeeldingen en gegevens uit mijn lokale omgeving verwijderen op verzoek.
Wat krijg ik precies bij de levering?
Je ontvangt een gestructureerd JSON-bestand (of meerdere bestanden, afhankelijk van je voorkeur) met alle geëxtraheerde data-velden (door jou aangeleverd). Deze data is schoon en geformatteerd voor gebruik door je interne systemen of datateams.
Kun je multi-page pakbonnen of complexe tabellen verwerken?
Ja. In tegenstelling tot standaard OCR-tools die moeite hebben met rijen die over meerdere pagina's lopen, is mijn proces voor 99% nauwkeurig in het identificeren van lange documenten, zodat elk lijnitem wordt vastgelegd en correct gecategoriseerd in de uiteindelijke JSON-uitvoer.