Voer LLaMA-modellen lokaal uit op je eigen hardware en ontgrendel snelle, private AI! Ik ben gespecialiseerd in het inzetten van LLaMA LLMs voor beginners en ontwikkelaars met behulp van llama.cpp, een lichte C/C++ inference engine die hoge prestaties lokale inference mogelijk maakt. Je krijgt een volledige setup op Windows en Linux. geen cloud, geen terugkerende kosten, en volledige controle over je AI-modellen.
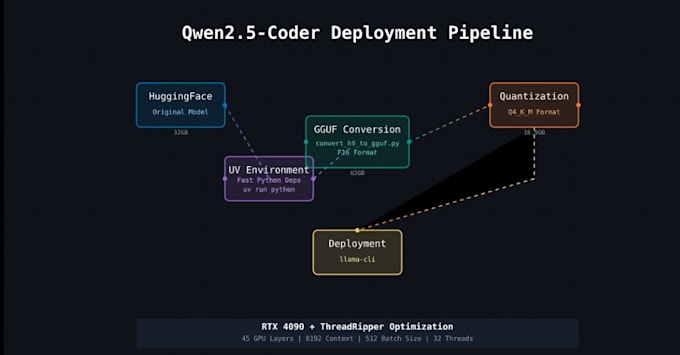
- Lokale installatie: Ik installeer en configureer de nieuwste LLaMA (2/3) of compatibele GGUF-modellen op jouw machine. Of je nu Windows, Linux of Mac gebruikt, ik regel de omgeving, dependencies en de installatie van llama.cpp of binary.
- GPU & CUDA optimalisatie: Met NVIDIA CUDA ondersteuning schakel ik GPU-versnelling (en multi-threading) in om de inference te versnellen. Door gebruik te maken van llama.cpp's optimalisaties en model quantization (4-bit/8-bit) verminderen we het geheugenverbruik zodat zelfs grote modellen soepel draaien (gequantiseerde modellen zijn veel lichter en behouden goede nauwkeurigheid).
- Fine-tuning & maatwerk data: In het Premium pakket tune ik je LLaMA-model verder op je eigen dataset met behulp van LoRA adapters (LoRA laat ons het model aanpassen door alleen de adaptergewichten te trainen).