Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD
India
Senior Data Engineer, Spark, Scala, AWS, Airflow, Kafka, Big Data
Ben je op zoek naar een betrouwbare PySpark Data Engineer om je ETL-pijplijnen te bouwen of te optimaliseren?
Je bent op de juiste plek.
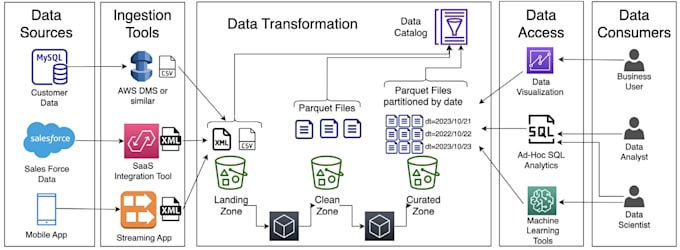
Ik ben Pankaj, een Data Engineer met meer dan 3 jaar ervaring bij Paytm, waar ik meer dan 200+ productie ETL-pijplijnen heb gebouwd die meer dan 5 TB/dag verwerken met behulp van PySpark, Airflow, AWS en Kafka.
Deze dienst richt zich 100% op het leveren van snelle, schaalbare en schone PySpark ETL-oplossingen voor jouw bedrijf.
Wat ik voor je kan doen
Waarom voor mij kiezen
Technologieën die ik gebruik
Heb je een maatwerk behoefte?
Stuur me gerust een bericht, ik reageer snel.
Laten we iets schaalbaars bouwen.

Automatische vertaling
Wat heb je van mij nodig om te beginnen?
Database/API-toegang, voorbeeldgegevens, SQL-logica of probleemomschrijving.
Kun je verbinding maken met mijn database of API?
Ja — MySQL, PostgreSQL, MongoDB, APIs, S3 en meer.
Optimaliseer je bestaande pijplijnen?
Ja — ik ben gespecialiseerd in runtime-optimalisatie en debugging.
Kun je AWS-diensten integreren?
Ja — Glue, S3, EMR, Lambda, Athena.
Kun je een NDA ondertekenen?
Ja — ik kan onder NDA werken indien nodig.