Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD

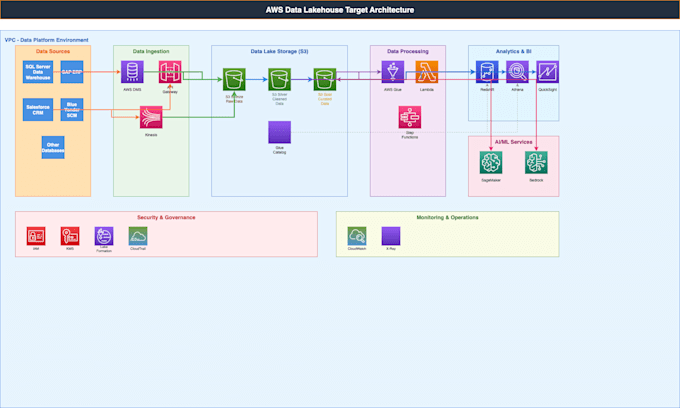
Senior Data Engineer: AWS, Azure, Spark, ETL Pipelines and Data Architecture
Skills
Bekijk mijn diensten

Senior Data Engineer
Alcon • Fulltime
Aug 2024 - Jan 2026 • 1 yr 5 mos
• Designed and implemented highly scalable real-time data pipelines using AWS Glue ETL, Step Functions, Lambda, and S3 for seamless data movement across layers while maintaining 99.9% uptime. • Engineered Spark optimizations within AWS Glue that reduced processing time by 30% and limited worker usage, leading to improved efficiency and $50K annual cost savings for performance analytics workloads. • Led cross-functional teams including data scientists and marketing analysts to deliver robust data solutions tailored to various business use cases, enhancing collaboration and project outcomes. • Automated workflows with Step Functions and Lambda for ad performance monitoring, reducing manual intervention by 80% through robust error handling and real-time alerting systems.
Associate Data Engineer
Publicis Sapient • Fulltime
Jun 2022 - Aug 2024 • 2 yrs 2 mos
• Streamlined performance analytics and reporting platform for Tesco, leading cross-functional teams to analyze and optimize marketing campaign data, increasing data accuracy by 20% and reducing reporting time by 30%. • Designed, developed, and maintained robust data pipelines and ETL processes using Hadoop, Azure Stack, and Databricks for processing large-scale marketing and transaction data, achieving 25% improvement in processing efficiency. • Implemented comprehensive data integration solutions and established data governance frameworks with advanced validation and cleansing processes, ensuring data quality and security standards for campaign performance tracking. • Technologies mastered: Spark, Python, Hadoop, Tableau, Azure Stacks, Databricks, PySpark, Spark SQL, Real-time Analytics, Marketing Data Processing, Jira, Splunk
Data Engineer
Bluefield Technologies Private Limited • Fulltime
Feb 2018 - Aug 2022 • 4 yrs 6 mos
• Created and managed Hive tables with optimized queries for processing high-volume transaction and event data, implementing partition-based child tables resulting in 40% performance improvement and significant cost savings. • Utilized Spark transformations during real-time data movement to STAGING layer for processing impression, click, and conversion events, demonstrating expertise with Text, Avro, JSON, Parquet, ORC, CSV, and XML formats. • Gained hands-on experience with Hadoop ecosystem components including MapReduce, HDFS, YARN, Sqoop, Hive, and HBase for processing large-scale marketing and advertising data with enhanced security protocols.
