Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD
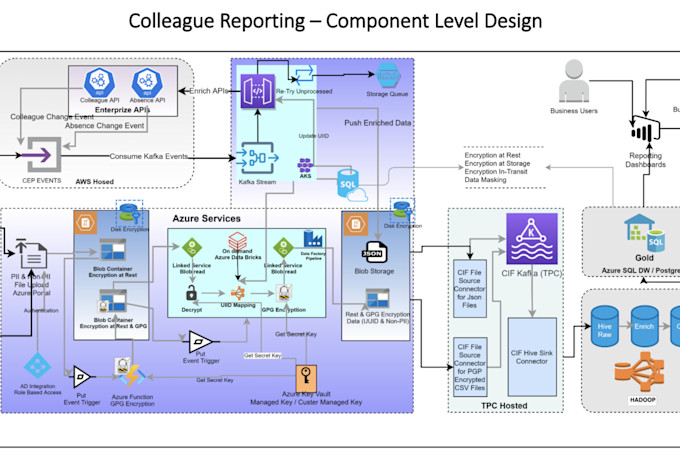
Senior Data Engineer: AWS, Azure, Spark, ETL pipelines en Data architectuur
Heb je moeite met trage of onbetrouwbare data pipelines? Ik ontwerp en bouw productieklare ETL pipelines op AWS en Azure die snel, schaalbaar en duurzaam zijn.
Wat je krijgt:
- End-to-end ontwerp en implementatie van ETL pipelines
- Apache Spark prestatieoptimalisatie (PySpark, Scala)
- AWS setup: Glue, Lambda, Step Functions, S3, Redshift
- Azure setup: Databricks, Data Factory, Azure Data Lake Gen2
- Data validatie, foutafhandeling en monitoring
- Volledige documentatie en overdracht
Ideaal voor:
- Bedrijven met trage of falende data pipelines
- Teams die migreren van on-premises naar AWS of Azure
- Projecten die Spark optimalisatie en tuning nodig hebben
- Real-time of batch ETL ontwikkeling
Waarom voor mij kiezen:
Meer dan 5 jaar ervaring in het bouwen van enterprise data pipelines in retail, IoT en finance. Ik heb pipelines verwerkt die miljoenen records per dag verwerken en breng diezelfde expertise naar jouw project.



Bestemmingsplatform:
Amazon Redshift
•
Amazon S3
Tools & platforms:
AWS Glue DataBrew