Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD


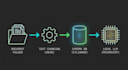

Stop leaking sensitive data to the cloud. Chat with your documents 100% locally and securely.
Are you tired of uploading confidential business documents, contracts, or research papers to generic cloud APIs? I build custom Retrieval-Augmented Generation (RAG) pipelines that run entirely on your local hardware or private servers. As a Data Engineer based in Germany, I specialize in building highly secure, GDPR-compliant AI architectures.
My Core Deliverables:
Perfect for legal teams, medical practices, or researchers needing secure knowledge extraction.
Please contact me before ordering to discuss your hardware specs!
Data Engineer, Local AI Specialist and Master of Urban Development
Talen
Do I need a high-end PC to run this local AI?
Yes. For smooth LLM inference (like Llama 3.1), a GPU with at least 8GB VRAM (e.g., RTX 3060/4060/5060) or an Apple M-Chip (16GB+ RAM) is required. CPU-only runs are possible but slow. Message me your hardware specs before ordering!
Is my data really 100% private and secure?
Absolutely. Unlike ChatGPT, this RAG pipeline runs entirely on your local machine. Your PDFs and internal documents are vectorized and stored in a local database (e.g., ChromaDB). Zero data is sent to OpenAI or any cloud API.
How do you prevent the AI from hallucinating?
I implement a strict RAG architecture with targeted System Prompts (Temperature 0.0). The LLM is forced to only use context extracted from your PDFs. If the answer isn't in your docs, the AI states it doesn't know, preventing fabricated facts.
What types of documents can the AI read?
I support PDF, TXT, CSV, and Markdown. For complex PDFs (like technical manuals or DIN standards), I use advanced parsing (PyMuPDF) to preserve layout. This ensures the embedding model receives clean, context-rich text chunks.
Does the AI support languages other than English?
Yes! I use state-of-the-art multilingual embedding models (BAAI/bge-m3) and LLMs (Llama 3.1). They excel in German, French, Spanish, etc. The AI can seamlessly read a German document and answer accurately in English, or vice versa.


