Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD


Automatische vertaling
Over deze dienst
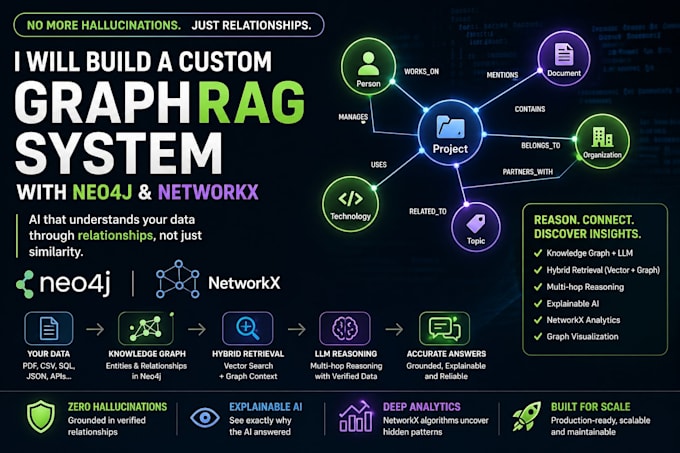
Als je AI moeite heeft om data van meerdere bronnen op een betekenisvolle manier te verbinden, heb je een beter systeem nodig dat relaties in je data introduceert. Ik bouw GraphRAG-systemen met Neo4j en NetworkX om AI-prestaties en redenering te verbeteren.
Basis
Doelgroep: Perfect voor het valideren van je datastructuur of een kleinschalige pilot.
Standaard
Doelgroep: Voor teams die hoge nauwkeurigheid van AI nodig hebben voor hun specifieke interne data.
Premium
AI Engineer
Talen
Automatische vertaling
Automatische vertaling
Wat maakt jouw GraphRAG-systeem anders dan standaard RAG of chatbot oplossingen?
Standaard RAG-systemen vertrouwen puur op vector similarity, wat vaak leidt tot irrelevante of hallucineerde antwoorden. Mijn GraphRAG-systemen gebruiken gestructureerde relaties in een knowledge graph (Neo4j) gecombineerd met vector search. Hierdoor kan de AI over verbonden data redeneren en de kwaliteit van de antwoorden verbeteren.
Hoe reduceer je hallucinaties?
Hallucinaties worden geminimaliseerd door: 1. Reacties te baseren op expliciete graph relaties 2. Antwoorden te beperken tot geverifieerde datapunten 3. Graph traversal te combineren met retrieval De AI verzint geen antwoorden — ze haalt ze uit je datastructuur.
Hoe nauwkeurig is het systeem vergeleken met ChatGPT of standaard bots?
Voor complexe, domeinspecifieke vragen behalen GraphRAG-systemen meestal 30–50% hogere nauwkeurigheid omdat ze: 1. Geverifieerde relaties gebruiken in plaats van gokken 2. context behouden over meerdere documenten 3. multi-hop redenering ondersteunen
Met welke data kun je werken?
Ik kan werken met de meeste gestructureerde en ongestructureerde dataformaten, waaronder: - PDFs (rapporten, onderzoeksartikelen, juridische documenten) - CSV / Excel datasets - JSON / APIs - SQL databases - Interne documentatie of wiki’s Als je data relaties bevat die verborgen zijn, is het een sterke kandidaat voor GraphRAG.
Heb ik technische kennis nodig om het systeem te gebruiken?
Nee. Voor de plannen Standaard en Premium lever ik een FastAPI backend met eenvoudige endpoints die je frontend of interne tools kunnen aanroepen. Je hoeft geen kennis van graphs of AI internals te hebben om het effectief te gebruiken.
Wat ontvang ik aan het einde van het project?
Afhankelijk van het plan kunnen de opleveringen omvatten: Graph schema (Neo4j) Data inlees pipeline Hybride RAG query systeem FastAPI backend NetworkX analytics laag (Premium) Graph visualisatie tools Documentatie + ondersteuning Alles is ontworpen om bruikbaar en uitbreidbaar te zijn, niet alleen als demo.
Kun je dit integreren met mijn bestaande systemen of frontend?
Ja. De plannen Standaard en Premium bevatten een API-laag, waardoor integratie met: Interne dashboards Chat interfaces Web apps Bestaande AI tools gemakkelijk mogelijk is.
Kun je het systeem aanpassen voor mijn exacte use case?
Absoluut. Elk systeem wordt op maat gemaakt voor jouw: - Data structuur - Query behoeften - Business logica Dit is geen one-size-fits-all chatbot — het is een op maat gemaakte redeneringsmotor.
Ondersteun je lokale/private LLMs?
Ja. Ik kan het systeem configureren om te werken met: 1. OpenAI (bijvoorbeeld GPT-modellen) 2. Anthropic Claude 3. Lokale modellen zoals Llama Dit is vooral handig voor privacygevoelige of on-premise implementaties.
Wat heb je van mij nodig om te beginnen?
Voor het starten heb ik nodig: 1. Je dataset (PDFs, CSV’s, etc.) 2. Een duidelijke probleemomschrijving (waar AI nu faalt) 3. (Optioneel) Voorbeeldvragen die je wilt dat het systeem beantwoordt Als je het niet zeker weet, stuur me een bericht en ik help je de structuur te bepalen.