Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD
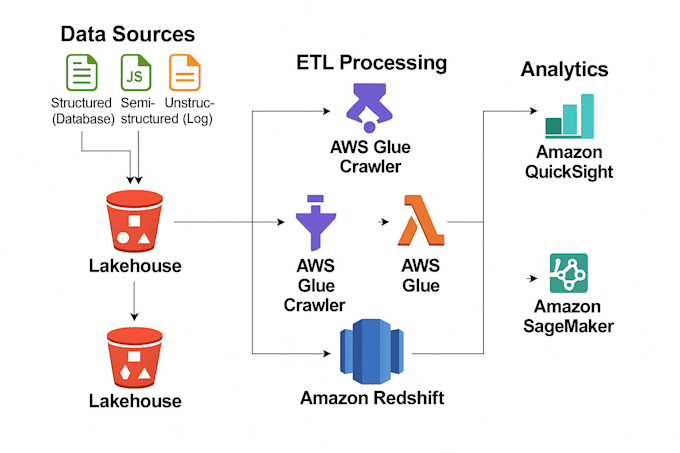
Ik ontwerp en bouw schaalbare data pipelines die aansluiten bij jouw bedrijfsbehoeften. Met Python, PySpark, SQL en AWS automatiseer ik data-inname, transformatie en opslag om schone, betrouwbare en analytics-geschikte data te leveren. Ik voer datakwaliteitscontroles uit zoals het detecteren van ontbrekende waarden, dubbele gegevens verwijderen, formaatverificatie en schema-validatie om de integriteit van de data te waarborgen.
Daarnaast maak ik interactieve dashboards en rapporten met Amazon QuickSight en Tableau om je te helpen KPI's te monitoren en gemakkelijk datagedreven beslissingen te nemen. Of je nu ETL-workflows, data-validatie, cloud-deployment of rapportage-oplossingen nodig hebt, ik lever geoptimaliseerde, schaalbare systemen.
Ik geef prioriteit aan duidelijke communicatie, tijdige levering en voortdurende ondersteuning om je data-infrastructuur mee te laten groeien met je bedrijf. Laten we je ruwe data omzetten in bruikbare inzichten!
Expertise:
Big data
•
Data validatie
•
etl
•
Transformatie
•
QA
•
SQL