Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD
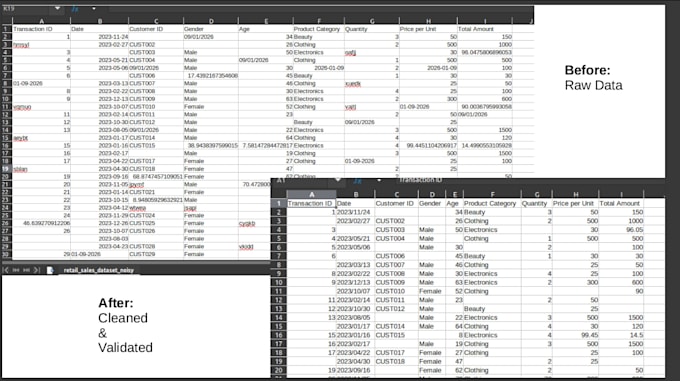
Databridge is a high-performance local data processing engine designed to transform messy, inconsistent data into a structured SQL warehouse. It automates the data cleaning process, replacing hundreds of manual hours with a single, secure tool.
Key Capabilities:
Python automation at its best: Ideal for e-commerce, finance, and marketing departments dealing with fragmented vendor reports.


Technologie:
Python
•
Overige
How does the engine handle non-standard headers?
It features a robust Regex-based normalizer. Any header like __&&UsER+nAME🥰 is automatically sanitized to user_name. It uses fuzzy matching to find the correct columns even if their names or order vary between files.
What are the specific data transformation rules?
We offer a growing library of types: int, float, date, str, plus specialized alpha (letters only) and identifier. All types use strict validation and error coercion to handle "dirty" data safely. More custom types are constantly being added to the engine.
How do your JSON templates work?
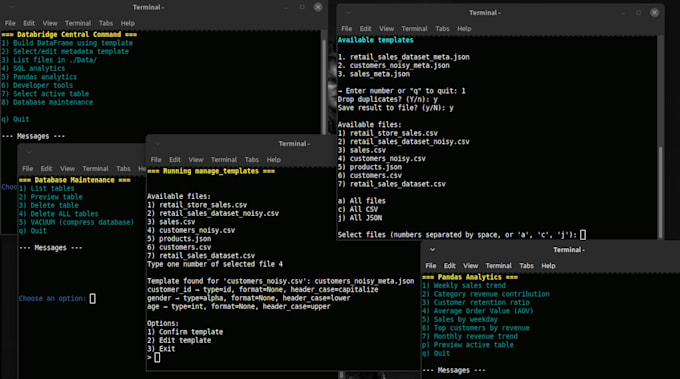
Templates act as a contract. The engine uses regex to find target columns regardless of their names or order. It then strictly casts data to your chosen types (int, float, date) and formats. If a row is missing data or fails validation according to the template, it is safely ignored.
Can I process lots of different files at once?
Yes, in the Enterprise tier, the "Batch Mode" allows you to point the engine at a folder. It will iterate through every file, ignore irrelevant data according to your template, and row-by-row build a consolidated database.
How do I manage the output database?
The tool includes a Database Service. You can switch between active tables, delete old datasets, and run the VACUUM command to defragment the SQLite file and reclaim disk space.
What are the system requirements?
This is a Python-based CLI tool. It requires Python 3.9+ installed on your machine. All processing is local, meaning performance depends on your CPU/RAM, but the engine is optimized for high-speed batch operations.