Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD
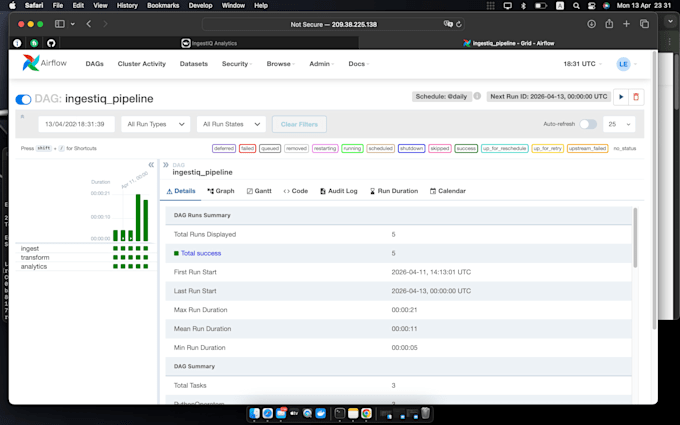
Data-infrastructuur & analytics
Ik bouw ETL/ELT-systemen die gefragmenteerde data omzetten in betrouwbare assets. Focus: stabiliteit en schaalbaarheid boven korte termijn oplossingen.
Waarom deze architectuur werkt:
Modulair ontwerp: Pipelines losgekoppeld van bronnen voor veilige schaalvergroting.
Consistentielaag: Validatie & statusbeheer voor 100% nauwkeurigheid.
Bronze/Silver opslag: Raw/processed lagen voor optimale prestaties.
Agnostische deployment: Docker-oplossingen voor elke cloud of on-premises setup.
Aangepaste dashboards: Streamlit-interface inbegrepen in elk project.
Samenwerking & grenzen: Ik lever autonome systemen met duidelijke limieten:
Scope: Behelst gedefinieerde bronnen & deployment. Nieuwe logica/integraties zijn aparte iteraties.
Betrouwbaarheid: Proactieve foutafhandeling inbegrepen. 24/7 monitoring of serveronderhoud zijn aparte diensten.
Eigenaarschap: Documentatie voor zelfstandig onderhoud.
Stack: Python, SQL, Airflow, Docker, Postgres, DuckDB.
Neem contact met mij op voordat je bestelt om af te stemmen!

Bestemmingsplatform:
PostgreSQL
•
MySQL
•
Overige
Tools & platforms:
Overige