Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD
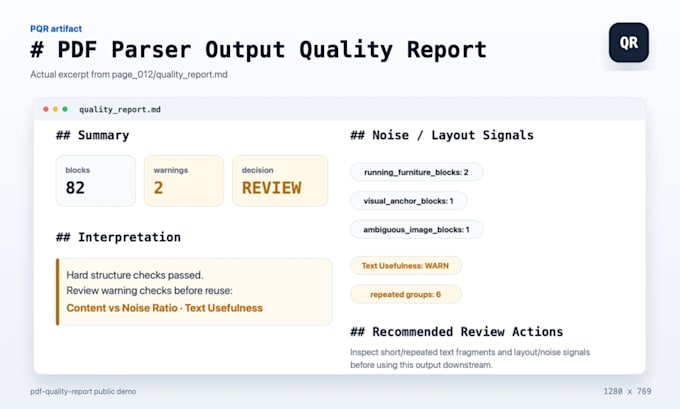
Je PDF-extractie output lijkt bruikbaar, maar je moet het eerst schoonmaken en controleren voordat je het gebruikt voor review, opruimen, schema-mapping of RAG-inname voorbereiding?
Ik beoordeel bestaande parser output van Docling, PyMuPDF, Unstructured of soortgelijke tools en maak:
Het werk begint bij jouw doel: welke velden belangrijk zijn, welke IDs of bronverwijzingen bewaard moeten blijven, en hoe je de output downstream gebruikt.
Wat ik nodig heb:
Wat ik niet dek:

Technologie:
Python
Automatische vertaling
Met welke parserformaten kun je werken?
Docling JSON is het beste. PyMuPDF, Unstructured, LlamaParse of vergelijkbare JSON/dict-achtige parseroutput kunnen ook werken na een snelle controle.
Bied je OCR of tabelreconstructie aan?
Niet standaard. Deze dienst is voor het reviewen en schoonmaken van bestaande parseroutput. Gescande documenten, OCR opschoning en complexe tabelreconstructie vereisen een aangepaste scope na een voorbeeldcontrole.
Is dit een RAG-systeem bouw?
Nee. Ik kan reviewbare JSON, Markdown of JSONL records voorbereiden voor inname, maar ik bouw de chatbot, retrieval systeem, vector database of answer-kwaliteits evaluatie niet.