Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD
Over mij,
Hoi,
Ik ben een Data Scientist en Junior Machine Learning Engineer met praktijkervaring in het bouwen van voorspellende modellen voor verschillende domeinen.
Ik maak een model dat toekomstige uitkomsten voorspelt met behulp van machine learning technieken.
De keuze van het model (Random Forest, Logistic Regression, XGBoost, etc.) hangt af van je dataset en het specifieke doel dat je wilt bereiken, of het nu classificatie, regressie of forecasting is.
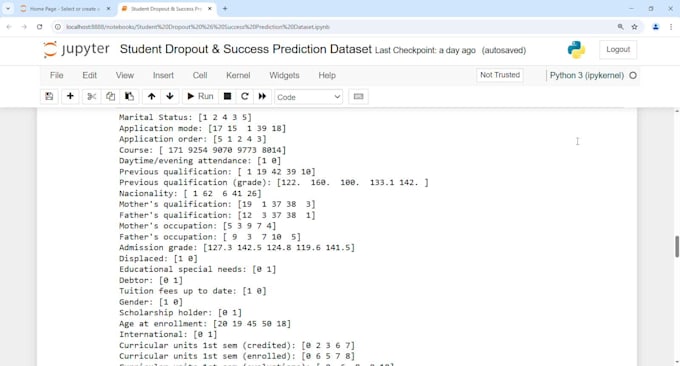
Een van mijn succesvolle projecten omvat het voorspellen van studentstatus (Dropout, Ingeschreven, Afgestudeerd) met 36 features zoals academische gegevens, demografische gegevens en financiële data met behulp van Random Forest.
Wat je krijgt:
Als je een project hebt dat data science of machine learning taken omvat, help ik je graag.
Ik heb waardevolle ervaring opgedaan met industrieel niveau projecten. Ik ben ook erg flexibel en makkelijk om mee te werken, en ik zet me in om waarde en duidelijke inzichten te leveren.
Stuur me een bericht voordat je bestelt, zodat we de beste oplossing voor jouw data kunnen vinden!



Programmeertaal:
Python
•
SQL
Frameworks:
Scikit-learn
•
Panda
•
Overige
API's:
Overige
Tools:
Jupyter-notitieboek
Automatische vertaling
Welke data heb ik nodig om te starten?
Ik heb je dataset nodig in een formaat zoals CSV of Excel, samen met een korte uitleg van wat elke kolom betekent en de uitkomst die je wilt voorspellen (bijvoorbeeld studentstatus, klantverloop, etc.). Hoe meer context je geeft, hoe beter ik het model kan afstemmen op jouw behoeften.
Welke machine learning algoritmes gebruik je?
Ik kies het algoritme op basis van je dataset en doel. Enkele veelgebruikte modellen die ik gebruik zijn Random Forest, Logistic Regression, Decision Trees, XGBoost en anderen. Als je een voorkeur hebt of een specifiek model nodig hebt, laat het me gerust weten!