Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD
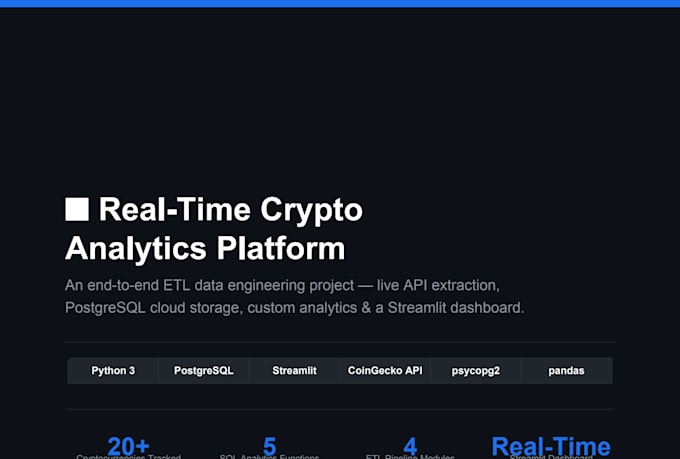
Ik zet data om in intelligence met machine learning en deep learning
Ben je op zoek naar nauwkeurige, productieklare ML-modellen die echte problemen oplossen? Je bent op de juiste plek.
Ik ontwikkel end-to-end machine learning en deep learning oplossingen in Python, van ruwe, rommelige data tot volledig werkende voorspellende modellen en data pipelines.
WAT JE KRIJGT
ECHTE PROJECTEN LEVERING
Schoon code. Duidelijke uitleg. Echte resultaten.
Stuur me een bericht voordat je bestelt, laten we je project bespreken!

Programmeertaal:
Python
•
SQL
Frameworks:
Scikit-learn
•
keras
API's:
Overige
Tools:
Jupyter-notitieboek
•
tensorflow
•
Excel
•
MLflow
•
Colab
Automatische vertaling
Wat voor soort ML-problemen kun je oplossen?
Ik kan een breed scala aan supervised en unsupervised ML-problemen oplossen, waaronder regressie (prijsvoorspelling, verkoopvoorspelling), classificatie (spamdetectie, churn voorspelling, enz.), clustering en anomalie detectie. Als je niet zeker weet of jouw probleem past, stuur me dan gerust een bericht en ik vertel je het.
Moet ik mijn eigen dataset aanleveren?
Ja, bij voorkeur lever je je dataset aan. Als je er geen hebt, kan ik een relevante openbare dataset zoeken (van Kaggle, UCI of open API's) voor jouw probleem. Hoe beter je data, hoe beter de nauwkeurigheid van je model — dus het delen van echte data geeft altijd de beste resultaten.
In welk formaat worden de deliverables geleverd?
Je ontvangt een schoon Jupyter Notebook (.ipynb) met volledige broncode, goed commentaar en visualisaties. Voor de Standard en Premium pakketten krijg je ook een PDF-rapport of modeldocumentatie. Alle bestanden worden geleverd als een ZIP-archief zodat alles georganiseerd en klaar voor gebruik is.
Kun je een specifieke modelnauwkeurigheid garanderen?
Geen enkele eerlijke ML-professional kan een vaste nauwkeurigheid garanderen; het hangt sterk af van de kwaliteit, grootte en complexiteit van je data. Wat ik wel garandeer, is dat ik de beste preprocessing, feature engineering en modeloptimalisatietechnieken toepas om de prestaties te maximaliseren. Ik laat je altijd de evaluatiemetrics zien.
Welke Python-bibliotheken en tools gebruik je?
Ik gebruik vooral scikit-learn, Pandas, NumPy, Matplotlib en Seaborn voor ML en data-analyse. Voor pipelines en databases gebruik ik PostgreSQL, psycopg2 en MySQL. Voor dashboards gebruik ik Streamlit. Voor deep learning taken gebruik ik TensorFlow/Keras. Alle bibliotheken zijn industrienorm en worden breed ondersteund.
Begrijp ik de code ook als ik niet technisch ben?
Absoluut. Elke notebook is geschreven met duidelijke, stapsgewijze commentaar die uitleggen wat elk blok code doet en waarom. Voor de Standard en Premium pakketten voeg ik ook een schriftelijke samenvatting van bevindingen en resultaten toe in eenvoudig Engels, zodat je de inzichten begrijpt, niet alleen de code.
Kan ik het model deployen zodat ik het live kan gebruiken?
Ja, cloud deployment en API-integratie zijn inbegrepen in het Premium pakket. Ik kan je model deployen als een Streamlit webapp of een REST API endpoint, zodat het klaar is voor gebruik in productie. Als je deployment op een specifiek platform nodig hebt (AWS, Render), stuur me dan een bericht voordat je bestelt zodat we de setup kunnen afstemmen.
Wat als ik iets op maat nodig heb dat niet in je pakketten staat?
Geen probleem. Stuur me je wensen en ik stuur je een aangepaste offerte die precies aansluit bij jouw behoeften. Of het nu gaat om een unieke dataset, een specifiek algoritme, een groter pipeline of een gecombineerd ML + dashboard project. Ik bespreek het graag en geef een passende prijs.
Worden mijn gegevens vertrouwelijk behandeld?
100% ja. Jouw data wordt uitsluitend gebruikt om jouw project te voltooien en wordt nooit gedeeld, gepubliceerd of hergebruikt in welke vorm dan ook. Als je een Non-Disclosure Agreement (NDA) wilt ondertekenen voordat je gevoelige data deelt, doe ik dat graag. Jouw privacy en databeveiliging worden serieus genomen bij elk project.
Hoe werken revisies?
Basic omvat 1 revisie, Standard 2, en Premium 3. Een revisie omvat aanpassingen binnen de bestaande scope, zoals het aanpassen van modelparameters, visualisaties of bugs oplossen. Het omvat niet het toevoegen van volledig nieuwe functies of algoritmes buiten de afgesproken scope.