Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD
Met hard werken en inspanning kun je alles bereiken
Ben je op zoek naar een technische expert om je cloud-infrastructuur te ontwerpen en high-performance ETL/ELT-pijplijnen te ontwikkelen? Je bent op de juiste plek.
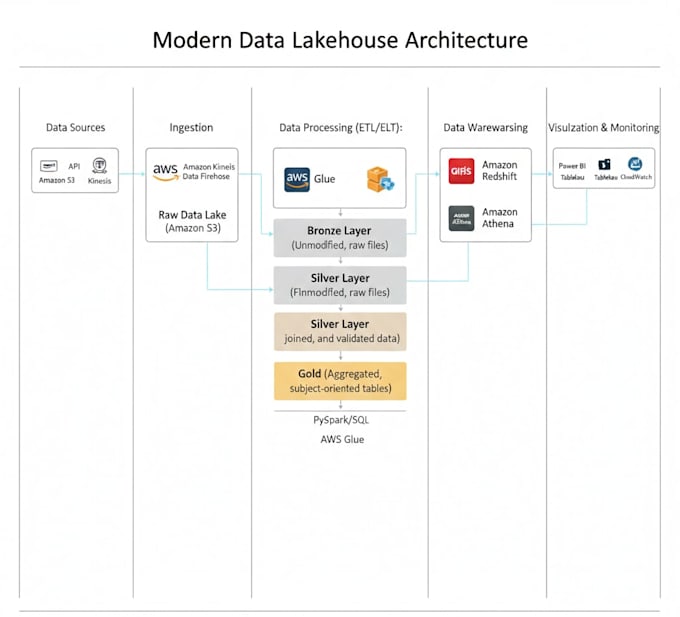
Ik ben gespecialiseerd in het ontwerpen en implementeren van end-to-end data-oplossingen. Of je nu een modern Data Lakehouse op Azure nodig hebt, een robuuste pijplijn op AWS, of complexe transformaties in Databricks, ik lever productieklare architecturen.
Mijn expertise & diensten:
De tech stack:

Expertise:
API integratie
•
Big data
•
Data-extractie
•
etl
•
SQL
•
NoSQL
Automatische vertaling
Kunt u ook de implementatiearchitectuur toelichten?
Ja, ik bied een volledige walkthrough van de architectuur. Ik leg de datastroom uit, de keuze van specifieke cloud-diensten (ADF, Databricks, etc.) en de reden achter het ontwerp, zodat jouw team het kan beheren in de toekomst.
Kun je zowel kleine als grote dataprojecten aan?
Absoluut. Ik ontwerp pijplijnen met schaalbaarheid in gedachten. Of je nu een startup bent die een eenvoudige API-naar-SQL-invoer nodig heeft of een grote organisatie die miljarden rijen verwerkt via Spark, ik pas de compute en opslag aan op jouw volume en budget.
Lever je technische documentatie bij de oplevering?
Elk project bevat een technische overzicht en setup-gids. Voor enterprise-grade, gedetailleerde documentatie (inclusief datadictionary en mapping documenten), vermeld dit tijdens onze discovery call zodat ik het in de scope kan opnemen.
Bied je doorlopende ondersteuning voor de oplossingen die je ontwikkelt?
Ja. Ik bied post-delivery support om te zorgen dat de pijplijn soepel draait in productie. Dit omvat troubleshooting van eerste runs, bugfixes en prestatieoptimalisatie. Langdurig onderhoud of maandelijkse support kan ook geregeld worden.
Hoe bepaal je de prijs voor een project?
De prijs is gebaseerd op drie factoren: het aantal datastromen, de complexiteit van de transformaties (ETL/ELT-logica) en de orkestratiebehoeften. Ik geef een transparante offerte na het bekijken van je dataschema en projectdoelen.
Hoe pak je een project aan om te starten?
We beginnen met een korte discovery fase waarin ik je datastromen en bestemmingseisen bekijk. Zodra de architectuur is goedgekeurd, zet ik de omgeving op, bouw ik de pijplijnen, voer ik strenge datavalidatie uit en lever ik de code met een technische walkthrough.