Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD
Ik ga datawetenschap of data-analyse doen
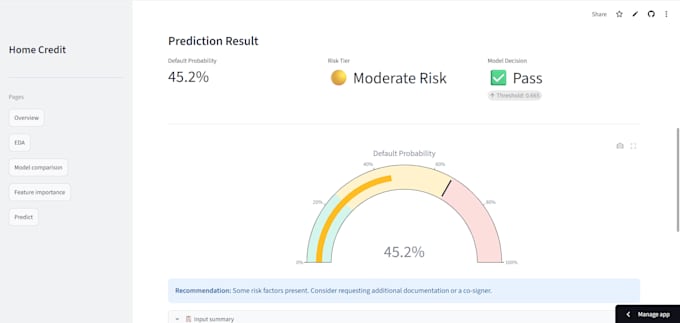
Live Demo: credit-risk-prediction-better.streamlit.app
GitHub: github.com/Niqar/Credit-risk-prediction
Heb je ruwe data liggen maar weet je niet hoe je die kunt omzetten in een werkend ML-model? Ik bouw voor jou een complete, productieklare machine learning pipeline van rommelige data tot een model dat echt presteert.
Wat ik lever:
Data cleaning & feature engineering (omgaan met ontbrekende waarden, encoding, schalen)
Modeltraining met LightGBM, XGBoost, Random Forest of Logistic Regression
Hyperparameter tuning met Optuna voor de beste prestaties
Volledige evaluatierapport (AUC, F1-score, precisie, recall, verwarringsmatrix)
Schoon scikit-learn pipeline die reproduceerbaar en klaar voor deployment is
Jupyter Notebook + gedocumenteerde Python code
GitHub repository (op aanvraag)
Waarom met mij werken:
Ik train niet zomaar een model en geef het je. Ik documenteer elke stap zodat je begrijpt wat er gedaan is en waarom, en ik zorg dat de pipeline schoon genoeg is om te hergebruiken of uit te breiden.
Bekijk mijn portfolio: credit-risk-prediction-better.streamlit.app
Voel je vrij om me een bericht te sturen voordat je bestelt. Ik bekijk je dataset en bevestig of ik kan helpen.



Programmeertaal:
Python
•
SQL
Frameworks:
Scikit-learn
•
keras
•
PyTorch
Tools:
Jupyter-notitieboek
•
opencv
•
tensorflow
•
Excel
•
Colab
Automatische vertaling
Met welk type data werk je?
Ik werk met gestructureerde/tabulaire data — CSV, Excel of SQL exports. Dit omvat classificatieproblemen (fraude, churn, kredietrisico) en regressieproblemen (prijsvoorspelling, verkoopprognoses). Voor beeld- of tekstdata, stuur me eerst een bericht zodat ik de scope kan beoordelen.
Wat als mijn dataset rommelig is of ontbrekende waarden heeft?
Dat is helemaal normaal — omgaan met rommelige data is onderdeel van mijn werk. Ik maak het schoon, behandel ontbrekende waarden, encodeer categorische features en schaal numerieke features als onderdeel van elk pakket.
Welke machine learning modellen gebruik je?
Voornamelijk LightGBM, XGBoost, Random Forest en Logistic Regression — afhankelijk van je data en doel. In de Standard en Premium pakketten train ik meerdere modellen en vergelijk ik ze zodat je het beste model krijgt.
Kan ik de code zelf hergebruiken of aanpassen?
Ja. Alle code is schoon, gecommentarieerd en gestructureerd als een goede scikit-learn pipeline — dus je kunt het gemakkelijk opnieuw trainen met nieuwe data of parameters aanpassen. Ik leg ook de belangrijkste onderdelen uit zodat je niet in het duister tast.