Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD
AI ML engineer
Je data bevat antwoorden.
De vraag is of jouw model ze daadwerkelijk vindt.
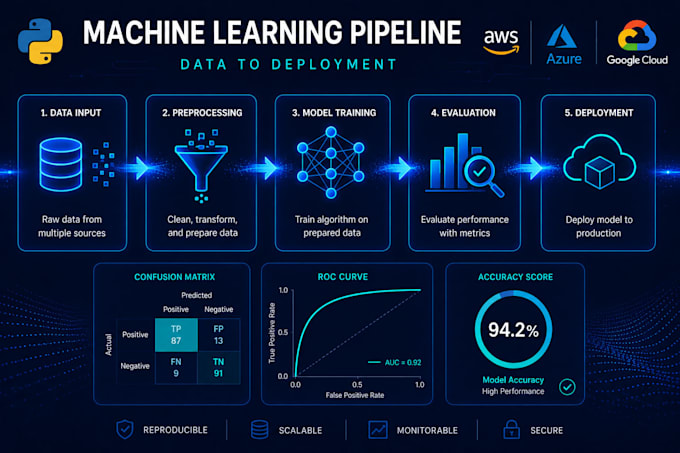
De meeste machine learning projecten mislukken niet door slechte data, maar door slechte preprocessing, verkeerde algoritmekeuzes en modellen die nooit worden ingezet. Ik bouw end-to-end ML-oplossingen die gaan van ruwe data tot een werkend, gedocumenteerd en productie-klaar model.
Wat je krijgt:
Ik heb modellen gebouwd die miljoenen records verwerken in finance, e-commerce en operations met Python, XGBoost, LightGBM, scikit-learn en meer.
Weet je niet precies wat jouw data nodig heeft? Stuur me een bericht voordat je bestelt. Ik vertel je precies welke aanpak bij jouw probleem past.


Programmeertaal:
Python
•
Colab
•
MLflow
Frameworks:
Scikit-learn
•
Google ML Kit
•
keras
•
PyTorch
•
Panda
Tools:
Jupyter-notitieboek
•
opencv
•
tensorflow
•
MLflow
•
Colab
Automatische vertaling
Welke informatie moet ik verstrekken om aan de slag te gaan?
Deel gewoon je dataset en vertel me wat je wilt voorspellen of classificeren. Als je specifieke zakelijke eisen, nauwkeurigheidsdoelen of beperkingen zoals geheugen of snelheid hebt, noem die dan ook. Hoe meer context je geeft, hoe beter ik het model voor je kan bouwen.
Welke bestandsformaten accepteer je voor data?
Ik werk met CSV, Excel, JSON, SQL databases en de meeste gangbare dataformaten. Als je data ergens anders staat, stuur me eerst een bericht en dan kijken we samen wat de beste manier is om het te verwerken.
Mijn dataset is heel klein. Kan je toch een model bouwen?
Ja, maar de aanpak verandert afhankelijk van de grootte. Voor kleinere datasets gebruik ik technieken zoals cross validation, regularisatie en eenvoudigere modellen die beter generaliseren. Ik vertel je altijd eerlijk of je data te beperkt is voor betrouwbare resultaten.
Kan ik het model gebruiken zonder Python te kennen?
Als je het Standaard of Premium pakket bestelt, krijg je volledige documentatie waarin uitgelegd wordt hoe alles werkt. Bij het Premium pakket krijg je ook een REST API, zodat je data naar het model kunt sturen en voorspellingen terugkrijgt vanuit elke applicatie zonder code te hoeven aanpassen.
Wat als de nauwkeurigheid van het model niet goed genoeg is?
Voor we beginnen stel ik realistische verwachtingen op basis van jouw data. Als de resultaten niet voldoen, werk ik door revisies om de prestaties te verbeteren. Ik lever niet en verdwijn niet zomaar.
Onderteken je NDA's of houd je mijn gegevens vertrouwelijk?
Ja. Jouw data en bedrijfsinformatie worden strikt vertrouwelijk behandeld. Als je een formele NDA wilt laten ondertekenen voordat je data deelt, doe ik dat graag.
Kun je werken met ongebalanceerde datasets of rommelige real-world data?
Dat is het meeste wat echt-world ML inhoudt. Ik behandel class imbalance met technieken zoals SMOTE en class weighting, en ik ga om met ontbrekende waarden, outliers en inconsistente formats als onderdeel van de preprocessing.
Naar welke cloudplatforms deploy je?
Ik werk vooral met Azure, GCP en AWS. Als je een voorkeur hebt of al een platform gebruikt, laat het me weten en ik zet het daar neer. Cloud deployment zit in het Premium pakket en is als add-on beschikbaar voor andere pakketten.