Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD





Automatische vertaling
Ben je klaar met handmatig documenten verwerken? Laat AI het in seconden doen.
Ik ontwikkel een aangepaste OCR- en Document Intelligence-pipeline die tekst uit PDFs, gescande bestanden, handgeschreven sheets en afbeeldingen haalt, verwerkt en analyseert, en levert schone, gestructureerde, productieklare output.
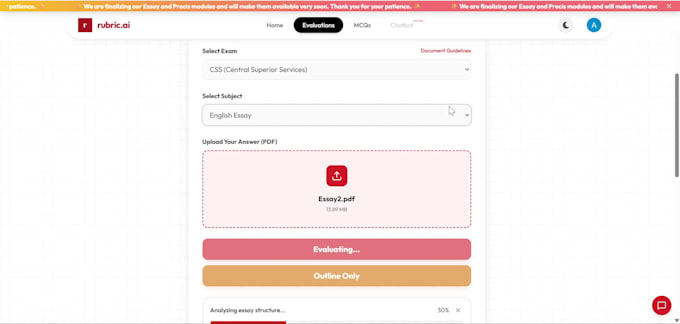
Ik heb echte OCR-systemen gebouwd en geïmplementeerd zoals Rubric Ai inclusief een AI-gestuurd examenbeoordelingsplatform en een geautomatiseerd factuurverwerkingsproces met echte gebruikers, geen zijprojecten.
Wat ik bouw: OCR-pipeline voor PDFs, afbeeldingen & gescande documenten Voorbewerking voor ruis, handschrift & lage kwaliteit invoer LLM-gestuurde analyse & slimme tekstextractie Geautomatiseerde annotatie & evaluatie engine Gestructureerde JSON/CSV output klaar voor integratie FastAPI backend & database-integratie
Perfect voor: Juridische, medische & financiële documentverwerking Examen-, beoordeling- & cijferautomatisering Factuur-, bon- & contractgegevens extractie
Waarom kiezen voor mij: Echte geïmplementeerde OCR-systemen, geen tutorials Handwriting, gemengde talen & slechte scans worden ondersteund Schone code, volledige broncode inbegrepen, op tijd geleverd
Stuur me een bericht en we bepalen de scope van je project voordat je bestelt.
Ai and Computer vision Solutions
Talen
Automatische vertaling
Automatische vertaling
Kun je een aangepast documentbeoordelings- of cijferingssysteem bouwen?
Absoluut. Ik heb rubric-gebaseerde LLM-evaluatie-engines gebouwd die documenten sectie voor sectie scoren en annoteren. Of het nu gaat om examenbeoordeling, contractreview of formuliervalidatie, ik kan een slim evaluatieproces op maat maken dat aan jouw criteria voldoet.
Welke soorten documenten kan jouw OCR-pipeline verwerken?
Mijn OCR-pipeline verwerkt PDFs, gescande afbeeldingen, gefotografeerde documenten en handgeschreven sheets. Het werkt ook met lage kwaliteit scans, gemengde talen en ruisende invoer, inclusief preprocessing om telkens schone, nauwkeurige tekst te garanderen.
Kun je het OCR-systeem integreren met mijn bestaande applicatie of database?
Ja. Ik bouw FastAPI REST backends die direct verbinden met je bestaande applicatie. Ik ondersteun MongoDB en PostgreSQL voor gestructureerde dataopslag en kan schone JSON- of CSV-uitvoer leveren die compatibel is met elk downstream systeem.
Wat is document intelligence en hoe verschilt het van basis OCR?
Basis OCR haalt alleen tekst eruit. Document intelligence gaat verder — met behulp van LLMs om de geëxtraheerde inhoud te analyseren, classificeren, annoteren en evalueren volgens vastgestelde criteria. Het verschil tussen een document lezen en het echt begrijpen.
Levert u de broncode en documentatie?
Ja, elke levering bevat volledige broncode, gedetailleerde inline commentaren en setup-documentatie zodat jouw team het systeem zelfstandig kan onderhouden en uitbreiden zonder afhankelijkheid van mij.
Hoe lang duurt het om een volledige document intelligence-pipeline te bouwen?
Een basis OCR-extractie-pipeline duurt 3 dagen. Een volledig document intelligence-systeem met LLM-analyse, annotatie-engine, API en database-integratie duurt meestal 7-10 dagen, afhankelijk van de complexiteit. Neem eerst contact op voor een nauwkeurige planning voor jouw project.