Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD
Systemen en ML-projecten C Python SQL Op tijd en geoptimaliseerd
Ben je verdrinkt in PDFs, facturen, formulieren of gescande afbeeldingen waarvan je data moet halen? Ik bouw productieklare AI-systemen die dat automatisch doen.
Ik ben een AI- en computer vision engineer met praktische ervaring in het bouwen van end-to-end deep learning pipelines, van ruwe data tot een werkende, inzetbare oplossing die je daadwerkelijk kunt gebruiken.
WAT IK BOUW
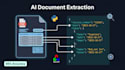
Intelligent Document Processing (IDP)
Haal gestructureerde data uit facturen, bonnetjes, contracten, medische formulieren, belastingdocumenten en elk ander aangepast PDF- of afbeeldingsformaat.
Op maat gemaakte OCR pipelines
Voorbij basis OCR, bouw ik AI-systemen die layout, tabellen, selectievakjes en handschrift begrijpen met TesseractOCR, PaddleOCR en deep learning.
Computer Vision & Object Detection
Op maat gemaakte YOLO (v8/v11) modellen, beeldclassificatie, segmentatie en object tracking getraind op jouw eigen dataset.
AI/ML modelontwikkeling
CNN, RNN, LSTM voor classificatie, regressie, NLP-tekstextractie en tijdreeksvoorspelling.
Model deployment & API
REST API via FastAPI of Flask, Docker containerisatie, cloud deployment (AWS, GCP), integratie met jouw frontend.
TOOLS & STACK
Python, PyTorch, TensorFlow, OpenCV, YOLO, PaddleOCR, Tesseract

Automatische vertaling
Moet ik trainingsgegevens aanleveren?
Het hangt af van het project. Voor veelvoorkomende documenttypes zoals facturen of bonnetjes, kan ik gebruik maken van vooraf getrainde modellen en deze aanpassen aan jouw formaat. Voor zeer aangepaste documenten of eigen lay-outs is een voorbeelddataset van 50–200 voorbeelden ideaal. Als je er geen hebt, kan ik je begeleiden in het verzamelen en
In welk formaat worden de geëxtraheerde gegevens geleverd?
Standaard lever ik gestructureerde JSON of CSV output. Als je het in een database, Excel-bestand of via API in je bestaande systeem wilt, kan dat geregeld worden — vermeld het gewoon wanneer je me bericht.
Hoe nauwkeurig zal de extractie zijn?
Nauwkeurigheid hangt af van de kwaliteit en complexiteit van het document. Voor schone, digitale PDFs ligt het meestal tussen 95–99%. Voor gescande of handgeschreven documenten is 85–95% realistisch. Ik test altijd op jouw daadwerkelijke documenten vóór oplevering en voeg een prestatieverslag toe.
Kunt u met documenten in andere talen dan Engels werken?
Ja. PaddleOCR ondersteunt meer dan 80 talen en ik heb ervaring met meertalige pipelines. Vermeld je taal wanneer je contact opneemt.
Wordt de code van mij?
Ja, 100%. Alle broncode, modelgewichten en documentatie zijn van jou. Ik behoud geen rechten op wat ik voor jou bouw.


