Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD

Automatische vertaling
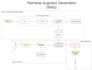
Ik ben een RAG Engineer die gespecialiseerd is in het ontwerpen en implementeren van productieklare Retrieval-Augmented Generation (RAG) pipelines voor bedrijfskennisbanken. Mijn systemen garanderen antwoorden met hoge fideliteit door LLMs (GPT-4, Llama, etc.) direct te verbinden met jouw data.
Ik transformeer onbetrouwbare prototypes in schaalbare, mission-critical applicaties.
Wat ik lever:
End-to-End RAG Ontwikkeling: Volledige pipeline bouw, van data-inname tot deployment.
Vector Database Expertise: Implementatie en optimalisatie met FAISS, Milvus en ChromaDB.
Geavanceerde Retrieval: Engineer Hybrid Search (Sparse + Dense) en Dynamische Context Injectie voor maximale relevantie en recall.
Schaalbaarheid & Prestaties: Ontwerp slimme Chunking, Embedding Update en Caching Strategieën om miljoenen documenten efficiënt te verwerken.
Gegarandeerde Kwaliteit: Ontwikkel Evaluatie Metrics & Dashboards om hoge relevantie, recall en systeemstabiliteit te meten en te waarborgen.
Ik bied bewezen, enterprise-grade RAG oplossingen om het potentieel van jouw data te ontsluiten.
Klaar voor een betrouwbaar AI retrieval systeem?
Neem contact op om je project te bespreken!
Data Science and Blockchain Engineer with L2 Experience
Talen
Automatische vertaling
Automatische vertaling
Welke technologie gebruik je?
Ik ga FAISS, Milvus, ChromaDB gebruiken en elke grote LLM (GPT-4, Claude, Llama)
RAG versus Fine-Tuning?
RAG is beter voor feitelijke, real-time antwoorden en is kostenefficiënter. Fine-Tuning verandert de stijl van het model.
Welke informatie heb je nodig?
Toegang tot je kennisbank, datavolume en de specifieke use case die je wilt bouwen (bijvoorbeeld Q&A chatbot).


