Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD

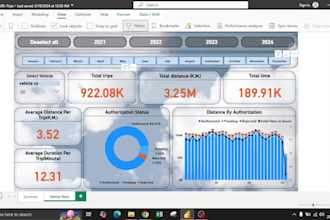
I will develop Azure, SQL, PySpark, Python and Power BI data solutions
Skills
Bekijk mijn diensten

Data Engineer
Paytm • Fulltime
Jun 2024 - Present • 2 yrs 1 mo
Data Engineer with 4+ years of experience in building scalable ETL/ ELT pipelines, data platforms, and analytics solutions in the FinTech domain. Strong expertise in Python, SQL, Apache Spark (PySpark), Databricks (Delta Lake, Unity Catalog), and Azure. Experienced in data ingestion, data transformation, data modeling, data validation, and data reconciliation across large-scale distributed systems. Proven experience in automating reconciliation processes (daily, monthly, yearly), reducing manual effort and improving data accuracy for financial reporting and audit compliance. Skilled in developing data pipelines for audit-ready datasets, financial analysis, and regulatory reporting. Hands-on experience with Power BI for dashboard development, data visualization, and business intelligence reporting, enabling stakeholders to derive actionable insights. Strong background in financial data analysis, KPI reporting, and delivering data solutions to multiple teams including audit, finance, and business stakeholders. Adept at requirement gathering, stakeholder management, and designing end-to-end data solutions that enhance data quality, governance, scalability, and performance. Developed reusable, parameterized data pipelines and ETL frameworks, improving development efficiency by 30% and enabling scalable and maintainable solutions. Developed and delivered analytics-ready datasets and Power BI dashboards, enabling stakeholders to track KPIs, campaign performance, and financial metrics for data-driven decision-making. Provided audit-ready data and supported multiple stakeholders including audit teams, analytics teams, and business units, reducing audit turnaround time by 30%. Built and optimized data ingestion frameworks and Spark-based workflows for batch and near real-time processing, reducing data latency by 35% and improving pipeline performance. Performed web scraping and data integration using Python to create structured, analytics-ready datasets.
