Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD
Waar data ontmoet intelligentie!
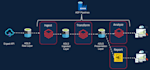
Of je nu te maken hebt met grote datasets, ETL-processen bouwt of cloudservices integreert, ik kan een op maat gemaakte oplossing maken die bij jouw behoeften past. Met jarenlange ervaring als Data Engineer zorg ik ervoor dat jouw pipeline geoptimaliseerd, veilig en schaalbaar is om groeiende datalasten aan te kunnen.
Wat ik aanbied:
Technologieën en talen die ik gebruik:
Talen:
o Python
o SQL
o Scala
o Shell scripting
Big Data tools:
o Apache Spark
o Apache Hadoop
o Apache Kafka
o Apache Airflow
o DBT (Data Build Tool)
o Snowflake
Databases:
o PostgreSQL
o MySQL
o MongoDB
o Redis
o Amazon Redshift
Cloud services:
Amazon Web Services (AWS)
Google Cloud Platform (GCP)
Microsoft Azure
Laat me je helpen de kracht van je data te ontsluiten.
Groeten,
Salman Sajid

Expertise:
Big data
•
Data-upload
•
etl
•
Normalisatie
•
Transformatie
•
SQL
Automatische vertaling
Kun je grote projecten aan?
Absoluut, ik kan grote projecten beheren. Neem gerust contact op om de details te bespreken voordat je een bestelling plaatst.
Wat moet ik aanleveren om een project te starten?
Deel alsjeblieft gedetailleerde informatie over je data, de verwachte resultaten en eventuele specifieke tools of platforms waarmee je wilt werken.


