Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD
VAKKUNDIGE FREELANCER TOEGEWIJD AAN KWALITEITSINHOUD
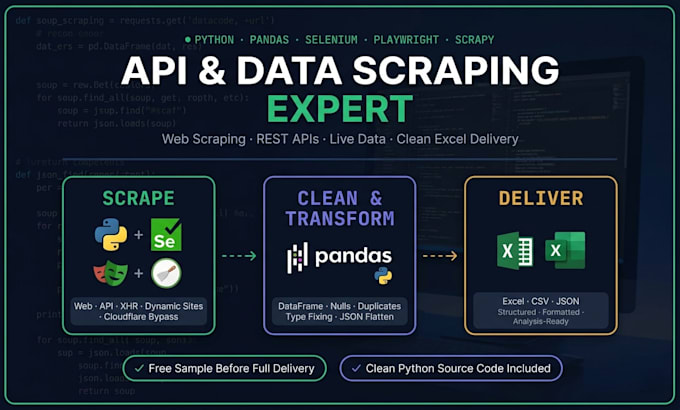
Ik haal dynamische websites en api-endpoints binnen
Heb je data nodig van een website, verborgen API of live feed, gestructureerd, schoongemaakt en klaar voor gebruik? Je bent op de juiste plek.
Ik verzorg zowel dynamisch web scrapen als API endpoint extractie van JavaScript-gerenderde pagina's tot reverse-engineered XHR/Fetch APIs en lever alles via een volledige Pandas schoonmaak- en formatteringspipeline.
WAT JE KRIJGT:
Dynamisch website scrapen
API endpoint discovery & reverse engineering (XHR/Fetch)
REST API scrapen tokens, auth headers, sessiebeheer
Cloudflare, Turnstile & anti-bot omzeilen
Real-time data zoals sportuitslagen, crypto, prijzen, lijsten
Geneste JSON geflatteerd naar gestructureerde sheets
Excel / CSV / JSON output
️ STACK:
Python · Pandas · Selenium · Playwright · Scrapy · Requests · BeautifulSoup · openpyxl
WAAROM IK:
Zowel web scrapen als API-extractie door één verkoper, volledige dekking
Gratis voorbeeld voorafgaand aan volledige levering
Herbruikbaar Python script inbegrepen bij elke opdracht
Alleen schoongemaakte, getypte en geformatteerde bestanden, geen ruwe dumps
Specialist in Turnstile & Cloudflare
Stuur me eerst een feasibility check, geen verplichtingen.


 (1)_kv3che.jpg)
 (1)_h3ydiz.jpg)
Technologie:
Python
•
Excel
•
Selenium
•
Beautiful Soup
•
Pandas
Type informatie:
Websites
Techniek:
Geautomatiseerd
Automatische vertaling
Q1: Wat is het verschil tussen web scraping en API scraping?
Web scraping haalt data direct uit de HTML van een website — handig voor pagina's zonder publieke API. API scraping onderschept de verborgen backend calls (XHR/Fetch requests) die een site maakt, voor schonere, snellere en betrouwbaardere data. Ik doe beide — afhankelijk van wat het beste werkt voor jouw site.
Q2: Kan je JavaScript-gerenderde of dynamische websites scrapen?
Ja. Ik gebruik Selenium en Playwright om JavaScript-pagina's volledig te renderen, oneindig scrollen, lazy loading en AJAX-content te verwerken voordat ik data haal — zodat niets wordt gemist.
Q3: Kan je Cloudflare of Turnstile bescherming omzeilen?
Ja. Ik heb ervaring met het vastleggen van Cloudflare Turnstile tokens, inclusief scroll-triggered en user-agent challenges — een van de meest complexe bot-beschermingssystemen die momenteel in gebruik zijn. Stuur me je target site voor een gratis haalbaarheidscheck.
Q4: Wat betekent "data cleaning en formatting" precies?
Voor levering doorloopt elke dataset een volledige Pandas pipeline: null-waarden worden afgehandeld, duplicaten verwijderd, datatypes gecorrigeerd, kolomnamen gestandaardiseerd, geneste JSON platgeslagen en Excel geformatteerd met juiste headers en kolombreedtes. Je ontvangt een afgewerkt, professioneel bestand — geen ruwe dump.
Q5: Ontvang ik de Python script?
Ja — elke opdracht bevat schone, gecommentarieerde, herbruikbare Python broncode zodat je de scraper zelf opnieuw kunt draaien zonder opnieuw te hoeven inhuren.
Q6: Welke outputformaten lever je?
Standaard Excel (.xlsx), CSV en JSON. Levering via Google Sheets mogelijk op aanvraag. Vermeld je voorkeur voorafgaand aan bestellen.
Q7: Is web scraping legaal?
Ik werk alleen met publiek toegankelijke data en scrape geen sites die dat expliciet verbieden in hun Terms of Service. Ik haal nooit privégebruikersgegevens of betaalmuren weg. Stuur me je target URL voor het bestellen, zodat ik de haalbaarheid en naleving kan bevestigen.
V8: Hoe begin ik?
Stuur me een bericht voordat je bestelt. Deel je target URL, de data-velden die je nodig hebt en de geschatte hoeveelheid. Ik bevestig de haalbaarheid, planning en eventuele technische uitdagingen — volledig gratis, zonder verplichtingen.