Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD



Automatische vertaling
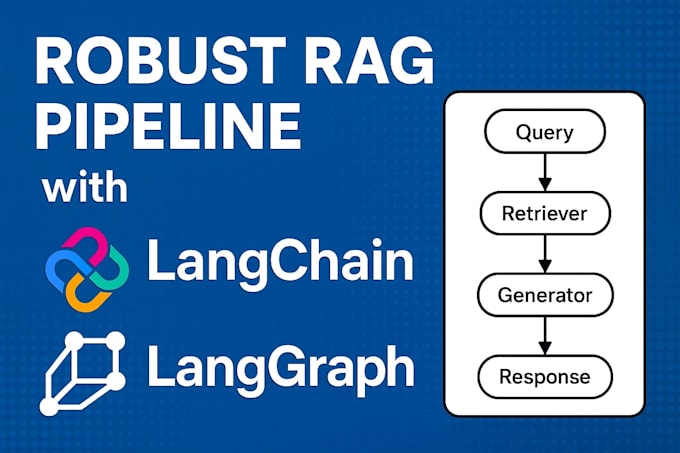
Ik ontwerp en bouw robuuste Retrieval-Augmented Generation (RAG) pipelines die nauwkeurige, contextbewuste antwoorden leveren uit jouw eigen data bronnen.
Geen hallucinaties. Geen breekbare scripts. Alleen productieklare architecturen die schoon, modulair en volledig gedocumenteerd zijn.
️ Wat je krijgt
Waarom met mij werken
Tech stack: Python · LangChain · LlamaIndex · Hugging Face · FAISS · Chroma · OpenAI API · Streamlit · FastAPI
Laten we jouw data bronnen en gewenste deployment stack bespreken
Machine Learning, Deep learning, Gen AI and Agentic AI
Talen
Automatische vertaling
Automatische vertaling
Kan ik mijn eigen data gebruiken (PDF’s, Notion, Google Drive)?
Absoluut. Ik kan connectors instellen voor jouw lokale of cloud-gebaseerde data bronnen.
Krijg ik de volledige broncode?
Ja. Alle code en environment bestanden worden meegeleverd en gedocumenteerd.
Kun je integreren met mijn bestaande app of API?
Ja — ik kan de RAG-pipeline omwikkelen met FastAPI endpoints of in je frontend embedden.