Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD
Gegevensanalyse
Niveau 1
Voldoet aan bepaalde prestatiecriteria en toont een sterke potentie op de marktplaats.
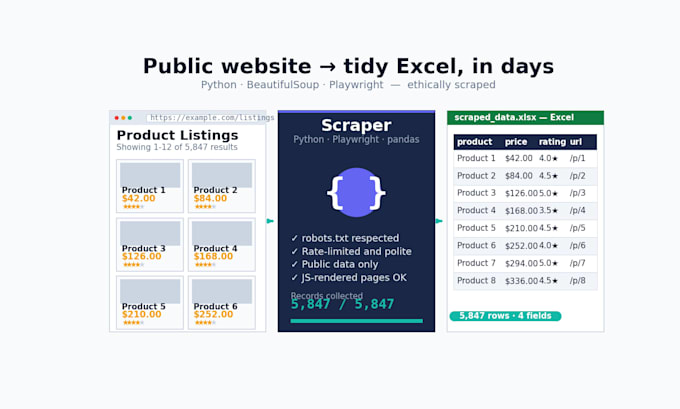
Stuur me URLs en de velden die je nodig hebt, ik bouw een Python scraper en lever de data als een schoon Excel- of CSV-bestand, klaar voor analyse.
Wat je krijgt:
- Een schoon .xlsx of .csv met één rij per record, genormaliseerde veldnamen
- Bron URL kolom voor elke rij (zodat je elke datapunten kunt controleren)
- Vastgestelde waarden (nummers, datums, valuta)
- Licht de-duplicatie en validatie
- Optioneel: de herbruikbare Python scraper script met een README (Premium)
Ik scrape:
- E-commerce productpagina's (Amazon, Shopify winkels, niche retailers binnen hun TOS)
- Vastgoed- en huuradvertenties
- Vacaturebanken (openbare vacatures)
- Gidsenwebsites (gouden gids, bedrijfsvermeldingen)
- Overheids- en regelgevende portals
- Openbare reviewsites
- Openbare sport- / statistiekwebsites
- Nieuws headlines en artikel metadata
Beide statische HTML-sites en JavaScript-rijke sites worden afgehandeld (Selenium / Playwright indien nodig).
Wat ik niet doe (vraag dit niet, dit schendt platform TOS of wetgeving):
- Sites scrapen die login vereisen (LinkedIn, Facebook, Instagram, X/Twitter, betaalde forums, betaalde databases)
- CAPTCHAs of anti-bot systemen omzeilen buiten redelijke rate-limiting
- Persoonsgegevens scrapen op manieren die GDPR / CCPA schenden


Technologie:
Google Sheets
Expertise:
API integratie
•
Data-extractie
•
Datastroom
Automatische vertaling
Wat houdt het basispakket in?
(1) Tot 500 records; (2) Enkele statische HTML-site; (3) Tot 8 velden per record; (4) Schoon .csv of .xlsx output
Wat houdt het standaardpakket in?
(1) Tot 5.000 records; (2) Meerdere pagina's of gepagineerde sites; (3) JavaScript-gerenderde inhoud (Selenium / Playwright); (4) Tot 15 velden per record; (5) Licht de-duplicatie + typecorrectie; (6) Schoon .xlsx output
Wat houdt het premium pakket in?
(1) Tot 50.000 records; (2) JS-rijke sites, complexe paginering, infinite-scroll handling; (3) Tot 30 velden per record; (4) Volledige data cleaning + validatie; (5) Herbruikbare Python scraper script met README zodat je het op aanvraag opnieuw kunt uitvoeren; (6) Uitvoeringsinstructies voor planning (cron / GitHub Actions / cl
Is webscraping legaal?
Het scrapen van publiek toegankelijke data is over het algemeen legaal in de meeste jurisdicties, maar de wetgeving varieert. De voorwaarden van elke site kunnen aanvullende restricties opleggen. Ik scrape alleen openbare data, respecteer `robots.txt`, en weiger opdrachten die TOS of platformbeleid schenden. Jij bent verantwoordelijk voor bevestiging
Kun je LinkedIn / Facebook / Instagram / X scrapen?
Nee. Deze platforms verbieden expliciet scraping in hun TOS en hebben er juridische procedures tegen gevoerd. Vraag het niet — de dienst wordt geannuleerd.
Kun je achter een login die ik geef scrapen?
Nee. Zelfs met jouw inloggegevens schendt geautomatiseerde toegang meestal de TOS van de site. Er zijn kleine uitzonderingen voor sites die jij bezit / waarvoor je schriftelijke toestemming hebt om te scrapen — stuur me eerst bewijs.
Heeft de site die ik wil scrapen anti-bot bescherming? Kun je dat omzeilen?
Ik respecteer rate limits en gebruik realistische browser headers, maar ik zal niet actief CAPTCHAs, IP-blokkering of fingerprinting systemen omzeilen. Als een site actief scrapers blokkeert, is dat een sterk signaal om het niet te doen.
Blijft mijn data privé?
Ja — ik deel of hergebruik nooit klantbestanden of scraping resultaten. NDA beschikbaar op aanvraag.
Kan ik de scraper zelf daarna draaien?
Premium bevat het Python script met een README. Je hebt Python 3.10+ nodig en ongeveer 5 minuten om het op te zetten.
Kun je herhaaldelijk (dagelijks / wekelijks) scrapen en de resultaten mailen?
Premium bevat planningsinstructies. Voor volledig beheerde scraping (ik host en mail je de resultaten), stuur me een bericht voor een aangepaste aanbieding.