Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD
Big data engineer
Niveau 2
Voldoet aan hoge prestatiecriteria en heeft een bewezen staat van dienst in het voldoen aan de verwachtingen van de klant.
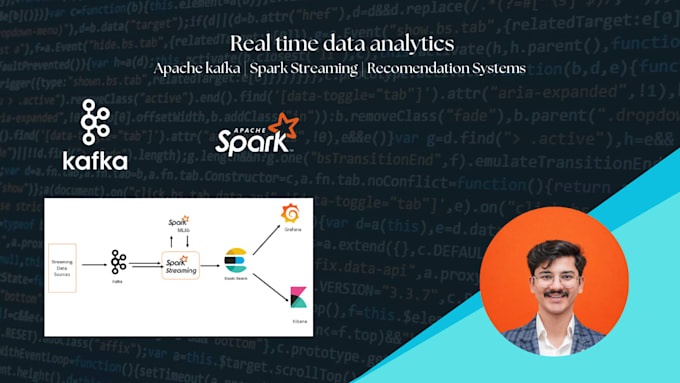
Moderne applicaties genereren enorme realtime data streams van websites, mobiele apps, IoT-apparaten en cloudplatforms. Het efficiënt verwerken van deze data vereist schaalbare streaming-architecturen en betrouwbare data pipelines.
Ik ben een Data Engineer gespecialiseerd in big data systemen en realtime verwerking, en ik help je bij het ontwerpen en implementeren van high-performance streaming pipelines met technologieën zoals Apache Kafka en Apache Spark.
Ik heb ervaring met het bouwen van gedistribueerde datasystemen en grootschalige analytics pipelines, waaronder een realtime muziek aanbevelingssysteem dat meer dan 100GB streaming data verwerkte met Hadoop en Spark, en realtime ETL pipelines met data warehousing voor enterprise analytics.
Technologieën
Voorbeeldgebruik
Ik richt me op het bouwen van schaalbare, betrouwbare en productieklare streaming pipelines die live data omzetten in bruikbare inzichten.
Neem contact met me op voordat je een bestelling plaatst om je wensen te bespreken.