Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD
Datawetenschap en kunstmatige intelligentie
Ben je op zoek naar meer dan alleen een basis NLP-script?
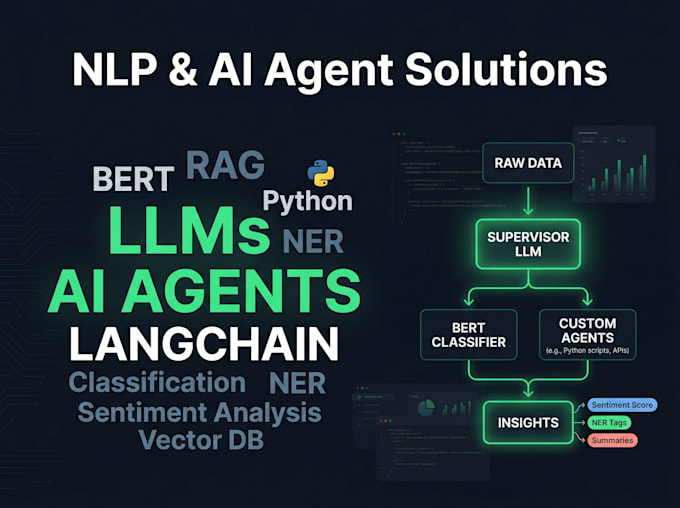
Ik ontwikkel end-to-end intelligente tekstsystemen, van klassieke NLP-pijplijnen tot fijn afgestelde BERT-modellen en productieklare AI-agenten aangedreven door LangGraph en LangChain. Of je nu een sentimentclassifier, een domeinspecifieke chatbot of een volledig multi-agent LLM-systeem nodig hebt, ik lever schone, gedocumenteerde en inzetbare oplossingen.
Wat ik aanbied:
1. NLP & Tekstanalyse
Tekstvoorbewerking: tokenisatie, stopwoordverwijdering, lemmatizatie (spaCy / NLTK)
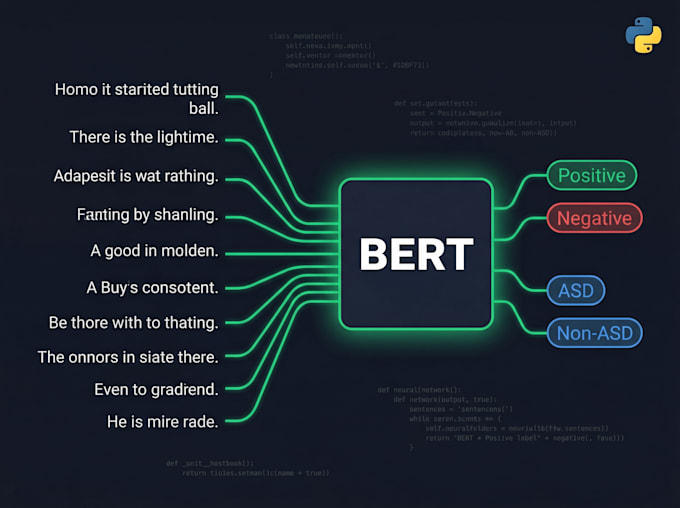
Tekstclassificatie & Sentimentanalyse (Naive Bayes, SVM, Logistieke regressie)
Named Entity Recognition (NER), trefwoord- & keyphrase-extractie
TF-IDF, N-gram analyse, woordfrequentie, co-occurrencenetwerken
Topic modeling: LDA, NMF, BERTopic
Tekstsamenhang & semantische gelijkenis
2. BERT & Transformer Fijn afstemmen
BERT, RoBERTa, DistilBERT, AraBERT finetunen op jouw eigen dataset
Sequentieclassificatie, tokenclassificatie, vraagbeantwoording
Trainingscurves, evaluatierapport (nauwkeurigheid, F1, verwarringsmatrix)
Modelgewichten opslaan & exporteren (HuggingFace-formaat, .pth, .zip)
3. AI-agenten & LLM-oplossingen
Multi-agent orchestratie met LangGraph, domeinspecifiek



Programmeertaal:
Python
•
MATLAB
•
SQL
•
Colab
Frameworks:
Scikit-learn
•
PyTorch
•
Panda
API's:
Overige
Tools:
Jupyter-notitieboek
•
opencv
•
tensorflow
•
Excel
•
Colab
Automatische vertaling
Q1: Met welk soort tekstgegevens kun je werken?
Elke domein — medische/klinische tekst, klantrecensies, social media posts, YouTube-comments, juridische documenten, academische papers, financiële rapporten, enquête-antwoorden. Als je tekst hebt, kan ik er iets mee bouwen.
Q2: Heb ik een gelabelde dataset nodig voor classificatie?
Voor gesuperviseerde taken (classificatie, sentiment) — ja, gelabelde data is nodig. Voor ongesuperviseerde taken (topic modeling, clustering, trefwoordextractie) — is ruwe tekst voldoende. Ik kan je ook adviseren over labelstrategie als je vanaf nul begint.
Q3: Kun je een RAG-systeem bouwen voor mijn documenten of kennisbank?
Ja — dit valt onder het Premium pakket. Ik zet een vector store op (FAISS of Chroma), koppel het aan je documenten en bouw een LangChain retrieval pipeline zodat je LLM vragen strikt uit je data beantwoordt.
Q4: Met welke LLMs werk je?
OpenAI GPT-3.5 / GPT-4, Groq (LLaMA 3, Mixtral), Google Gemini, Mistral. Ik werk met welke je ook hebt of al API-toegang voor hebt. Ik kan ook open-source lokale modellen gebruiken via Ollama als je geen API-kosten wilt.
Q5: Kan ik de code zelf draaien en aanpassen?
Absoluut. Alle opleveringen zijn schone, goed commentaar gevulde Jupyter/Colab notebooks. Ik schrijf code voor mensen, niet alleen voor machines. Je begrijpt elke stap, en ik leg graag alles uit na oplevering.
Q6: Kan ik het model of de agent als API of webapp deployen?
Basis deployment (FastAPI endpoint of Streamlit app) kan als extra worden toegevoegd. Voor volledige cloud deployment (AWS, GCP, Hugging Face Spaces) neem je contact met me op voor een aangepaste offerte voordat je bestelt.