Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD
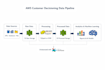
Ik ben een Senior Data Engineer met meer dan 6 jaar ervaring in het ontwerpen van schaalbare data pipelines en cloud data platforms. Ik ben gespecialiseerd in het bouwen van betrouwbare ETL-workflows, het transformeren van ruwe data naar gestructureerde datasets en het mogelijk maken van analytics-ready data systemen.
Ik kan je helpen met:
- ETL pipeline ontwikkeling met Python, SQL en Pyspark
- Data-inname van API's, bestanden en databases
- Data transformatie en optimalisatie
- Cloud data pipelines met AWS (S3, EMR, Redshift, Glue, Kinesis, Athena)
- Lakehouse architectuur (Bronze, Silver, Gold lagen)
- Data warehouse integratie en prestatieoptimalisatie
Ik richt me op het bouwen van efficiënte, schaalbare en productieklare data pipelines die analytics, rapportages en machine learning workflows ondersteunen.
Als je hulp nodig hebt bij het ontwerpen of verbeteren van je data pipeline of data platform, neem dan gerust contact op voordat je een bestelling plaatst.

Warehouse Platform:
Snowflake
•
redshift
•
PostgreSQL / Greenplum
Projecttype:
Nieuwbouw
