Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD
Laten we machine learning laten werken voor jouw doelen!
Over Mij
Hoi! Ik ben Sivanandham, een Machine Learning Specialist met een bewezen achtergrond in financiële voorspellingen, aandelenmarktvoorspellingen en data-gedreven automatisering. Met meer dan 2 jaar praktische ervaring in Artificial Intelligence, Machine Learning, Data Analyse, Data Science en AI-systemen.
Ik heb meer dan 25 echte ML-projecten afgerond die daadwerkelijk bedrijfsproblemen oplossen, niet alleen academische demo's.
Diensten die ik aanbied:
ML Model Ontwikkeling: Classificatie, Regressie
Pipeline Stappen: Data-inname, Data Cleaning & Preprocessing, Feature engineering, Model training, Hyperparameter tuning, Validatie & Voorspelling
Model Training & Evaluatie: Nauwkeurigheid, F1-score, ROC-AUC
Model Optimalisatie: Evaluatiemetrics, GridSearchCV
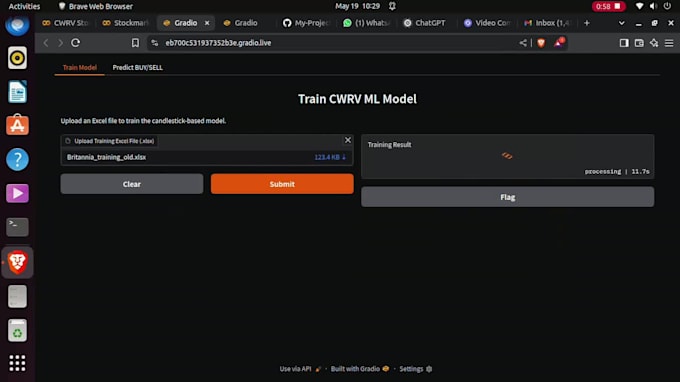
Model Deployment: Gradio-gebaseerde apps, lokale deployment
Tools & Technologieën:
Talen & Bibliotheken: Python, Pandas, NumPy, Matplotlib, Seaborn, Gradio, Excel, Scikit-learn
ML Algoritmes: Decision Trees, Support Vector Machine (SVM), Logistieke / Lineaire Regressie, Gradient Boosting, Cross-Validation, Grid Search
Versiebeheer: GitHub
Tip: Neem vooraf contact op met mij met je dataset, doelen en verwachtingen zodat ik het juiste plan en de juiste planning voor je kan maken




Programmeertaal:
Python
•
Colab
Frameworks:
Scikit-learn
•
PyTorch
•
Panda
API's:
Google Cloud Vision API
Tools:
Jupyter-notitieboek
•
opencv
•
Excel
•
MLflow
•
Colab
Automatische vertaling
Kun je werken met mijn ruwe dataset, of moet deze schoon zijn?
Ja, ik kan werken met ruwe data. Ik bied volledige data cleaning (ETL), preprocessing en transformatie om je dataset ML-klaar te maken — inclusief het omgaan met ontbrekende waarden, outliers en formatteringsproblemen.
Welke deliverables ontvang ik?
Je ontvangt Python-code (schoon en goed gecommentarieerd), prestatievisualisaties (confusiematrix, ROC-curve, feature importance), modeluitleg en deployment-klare bestanden.
Hoe zorg je dat het model goed presteert?
Ik gebruik bewezen technieken zoals cross-validation, train-test splits, bias-variance analyse en hyperparameter tuning (GridSearchCV) om geoptimaliseerde en robuuste modellen te bouwen.
Hoe kies ik tussen Basic, Standard en Advanced pakketten?
● Basic is ideaal voor eenvoudige toepassingen of beginners. ● Standard omvat volledige preprocessing, onbalans aanpak en tuning — perfect voor kleine bedrijven. ● Advanced biedt productieklare modellen, vergelijking van meerdere algoritmes en UI — ideaal voor professionals en onderzoeksprojecten.
Blijft mijn data privé?
Absoluut. Jouw data wordt als vertrouwelijk behandeld en wordt nooit gedeeld of hergebruikt.
Hoe weet ik dat jouw service betrouwbaar is?
Met meer dan 25 echte ML-projecten, geavanceerde training (6 maanden AI-certificering van Novi Tech) en bewezen bedrijfsresultaten (bijvoorbeeld 2166% groei met ML-inzichten), lever ik gestructureerde, uitlegbare en impactvolle modellen die op jouw doelen zijn afgestemd.
Kun je documentatie of notebook-achtige uitleg leveren?
Ja. Ik kan het project leveren in een Jupyter Notebook-formaat of Google Colab met stapsgewijze uitleg, commentaar en visuele outputs voor beter begrip en hergebruik.
Welke grootte van dataset kan je aan?
Ik kan efficiënt werken met kleine tot middelgrote datasets. Op maat gemaakte aanbiedingen kunnen worden gedaan om optimale prestaties te garanderen met behulp van efficiënte geheugentechnieken.
Welke specifieke data science diensten bied je aan?
Ik bied een scala aan diensten, waaronder data cleaning en preprocessing, exploratieve data-analyse, voorspellende modellering, fine tuning, ontwikkeling van machine learning algoritmes, datavisualisatie en bruikbare inzichten.
Hoe garanderen jullie de vertrouwelijkheid en veiligheid van mijn gegevens?
Jouw data wordt met strikte vertrouwelijkheid behandeld. Alle gevoelige data wordt verwerkt in beveiligde omgevingen en wordt niet online geüpload of via online platforms verwerkt: jouw data is alleen toegankelijk voor jou en de Jupyter Notebook die op mijn laptop draait.