Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD
Specialist in spreadsheet schoonmaak
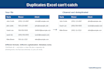
De ingebouwde "Remove Duplicates" functie van Excel vindt alleen dubbele rijen als de hele rij exact overeenkomt. Het vindt geen duplicaten als je lijst waarden bevat met:
Ik stel een paar vragen om je data te begrijpen, daarna merge ik duplicaten volgens jouw specificaties en standaardiseer ik de formaten. Ik stuur je een schone spreadsheet terug en een lijst van alles wat verwijderd is.
Met de hogere pakketten vind ik vermoedelijke duplicaten op basis van dingen zoals:
Excel en CSV worden beide ondersteund. De output matcht je input formaat. Metadata van bestanden wordt bewaard.
Je bestand wordt verwerkt voor je bestelling en na levering verwijderd voor privacy en veiligheid

Automatische vertaling
Wat wordt bedoeld met "100 Items Cleaned"?
Je kunt dat negeren. Het is iets dat Fiverr er automatisch bij zet voor dit soort werk. De enige limieten zijn het totale aantal rijen in de tier-beschrijvingen.
Welke soorten duplicaten vindt deze dienst die Excel's ingebouwde functie niet kan vinden?
Excel's "Remove Duplicates" vereist dat de hele rij exact overeenkomt karakter voor karakter. Als je data verschillen heeft in formatting van telefoonnummers, gemengde hoofd- en kleine letters in e-mails, trailing spaties, of extra metadata kolommen zoals Created Date of Row ID die anders identieke rijen onderscheiden, houdt Excel beide.
Accepteer je ook CSV-bestanden naast Excel?
Ja, zowel xlsx als csv worden ondersteund. De output matcht het formaat dat je hebt gestuurd: Excel in, Excel uit (één bestand met meerdere tabbladen); csv in, csv uit (losse bestanden voor de schoongemaakte data en de verwijderde rijen, samengevoegd in een zip-bestand)
Hoe groot kan een bestand zijn dat je aankunt?
Basis behandelt tot 10.000 rijen. Geavanceerd tot 50.000 rijen. Premium tot 100.000 rijen.
Kun je duplicaten vinden die niet helemaal identiek zijn?
Ja, dat wordt gedaan voor zowel het Advanced als het Premium pakket. "Bob Smith" wordt beschouwd als een vermoedelijke match van "Robert Smith", bsmith@gmail.com wordt beschouwd als een vermoedelijke match van bsmith@gamil.com, enzovoort.
Wat staat er in het data quality rapport van het Premium pakket?
Een schriftelijke samenvatting van de patronen van duplicaten die ik heb waargenomen in je bestand (bijvoorbeeld welk percentage afkomstig is van variaties in telefoonformaten versus gemengde hoofd- en kleine letters in e-mails versus metadata-kolom noise), en specifieke aanbevelingen om toekomstige duplicaten te voorkomen.
Wat moet ik doen als ik niet tevreden ben met het resultaat?
Stuur me een bericht en ik zorg dat het goed komt.
