Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD
Python Automation, API Integration, Data Extraction, LLM Workflows
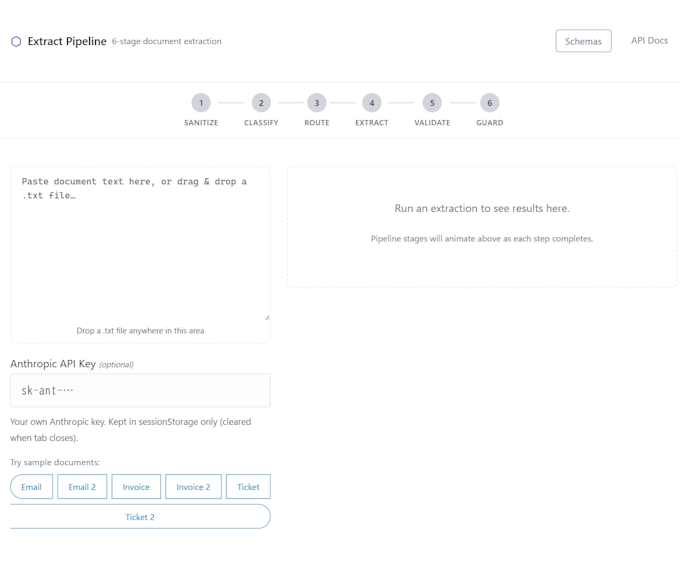
Need to extract structured data from messy documents? I will build a Python pipeline that turns unstructured files into clean, validated output.
LIVE DEMO: Try it at extract-pipeline.onrender.com
WHAT I EXTRACT FROM:
- PDFs, Word documents, and spreadsheets
- HTML pages and email bodies
- API responses and raw text files
WHAT YOU GET:
- Clean, structured output in CSV, JSON, or database
- Pydantic validation for data quality
- Error handling and logging
- Python source code you fully own
STANDARD and PREMIUM also include:
- YAML schema registry for flexible field mapping
- Multi-format support in a single pipeline
- Automated test suite
MY BACKGROUND:
- 8,000+ automated tests across all projects
- Experience with OpenAI, Anthropic, and Gemini APIs
- Bilingual: English and Japanese
HOW IT WORKS:
1. Share sample documents and describe the output you need
2. I confirm scope and build your extraction pipeline
3. You receive working code with validated sample output
Message me before ordering so we can align on scope.

Technologie:
Python
What file formats can you process?
PDF, Word (docx), Excel, HTML, CSV, JSON, plain text, and email (eml/msg). For scanned documents, I can integrate OCR. Share a sample and I will confirm compatibility.
How do you ensure data quality?
I use Pydantic schema validation to catch errors at extraction time. Every field is type-checked and validated before output. You get a report showing pass/fail rates.
Do you provide support after delivery?
Yes. Bug fixes are free for 7 days after delivery. If you need changes beyond the original scope, we can discuss a new order.