Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD
Schoon, analyseer en visualiseer je data in één oplossing
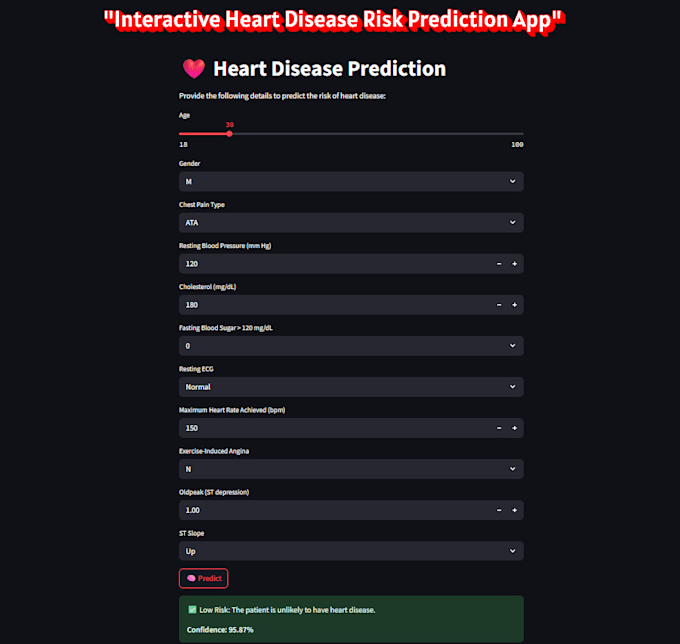
Ik voer volledige data-analyse uit en bouw machine learning modellen om je te helpen nauwkeurige, data-gedreven voorspellingen te maken met Python, Pandas en scikit-learn.
Van data schoonmaken, exploratieve data-analyse (EDA), en omgaan met ontbrekende waarden tot het trainen van ML-modellen en ze implementeren met Flask of FastAPI, ik bied end-to-end machine learning oplossingen op maat van jouw behoeften.
Wat je krijgt:


Technologie:
Excel
•
Google Sheets
•
Python
•
SQL
Automatische vertaling
Q: Met welk soort data kun je werken?
A: Ik kan werken met gestructureerde datasets zoals CSV, Excel, JSON of SQL databases. Of het nu gaat om sales, gezondheidszorg, marketing, financiën of andere domeinen — ik help je data schoonmaken, analyseren en modelleren.
Q: Welke machine learning modellen gebruik je?
A: Ik gebruik populaire ML-modellen zoals Linear Regression, Logistic Regression, Decision Trees, Random Forest, XGBoost, Support Vector Machines (SVM), KNN en meer — afhankelijk van je data en doelen.
Q: Welke tools en libraries gebruik je?
A: Ik gebruik vooral Python met libraries zoals Pandas, NumPy, matplotlib, seaborn, scikit-learn, XGBoost, en voor deployment: Flask of FastAPI.
Q: Leg je de resultaten aan mij uit?
A: Absoluut! Ik bied duidelijke visualisaties, samenvattende rapporten en uitleg van de modelresultaten zodat je begrijpt wat het model doet en wat de voorspellingen betekenen.
Q: Kan je het model als API deployen?
A: Ja, in het Gold pakket bied ik API-integratie met Flask of FastAPI zodat je model in applicaties of websites gebruikt kan worden.
Q: Ontvang ik de source code en modelbestanden?
A: Ja, ik lever het volledige Jupyter Notebook, het getrainde modelbestand (.pkl of .joblib), en eventuele extra bestanden zoals rapporten of visualisaties — afhankelijk van jouw gekozen pakket.
Q: Kan je omgaan met ontbrekende waarden en outliers?
A: Ja, ik identificeer en behandel ontbrekende data en outliers volgens best practices om je dataset schoon en klaar voor modellering te maken.