Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD
Ik lever Kwaliteit! 24 uur beschikbaar
Niveau 2
Voldoet aan hoge prestatiecriteria en heeft een bewezen staat van dienst in het voldoen aan de verwachtingen van de klant.
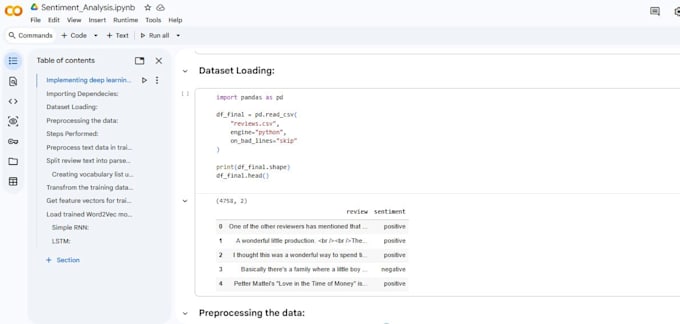
Ik bied professionele end-to-end sentimentanalyse oplossingen met Python en Natural Language Processing (NLP) voor bedrijven, startups en onderzoekers die bruikbare inzichten uit tekstdata willen halen. Ik werk met klantrecensies, social media content, enquêtes, supporttickets en feedbackgegevens om sentiment- en opinietrends te ontdekken die datagedreven besluitvorming ondersteunen.
Mijn werkwijze omvat geavanceerde tekstvoorbewerking (normalisatie, tokenisatie, stopwoordverwijdering, lemmatization), feature engineering met TF-IDF, n-grams of woordembeddings, en modelontwikkeling met machine learning en deep learning algoritmes zoals Logistic Regression, SVM, Naive Bayes en LSTM-gebaseerde architecturen. De modellen worden geëvalueerd met accuracy, precision, recall, F1-score en confusion matrices om betrouwbare prestaties te garanderen.
Je ontvangt schone, modulaire en goed gedocumenteerde Python code, reproduceerbare experimenten en visuele analytics voor zakelijke interpretatie. Ik ondersteun CSV, Excel, JSON en tekstformaten en kan oplossingen op maat maken voor binaire of multi-class sentimentclassificatie, schaalbaarheid en toekomstige implementatie.
Neem contact met me op voordat je bestelt om de projectomvang, datasetgrootte,


Automatische vertaling
Wat voor soort sentimentanalyse bied je aan?
Ik bied binaire (positief/negatief) en multi-class (positief/neutraal/negatief) sentimentanalyse aan met machine learning en deep learning modellen, afhankelijk van de complexiteit van het project en de datagrootte.
Welke programmeertaal en tools gebruik je?
Ik gebruik Python met industriestandaard NLP- en ML-bibliotheken zoals NLTK, SpaCy, Scikit-learn, TensorFlow/Keras, Pandas en NumPy.
Kunt u overweg met grote datasets?
Ja. Ik kan grote datasets (50.000+ records) efficiënt verwerken en modellen optimaliseren voor prestaties en schaalbaarheid.
Bied je ook deep learning–gebaseerde sentimentanalyse aan?
Ja. Voor geavanceerde eisen bouw ik LSTM- of embedding-gebaseerde deep learning modellen om hogere nauwkeurigheid te behalen op complexe tekstdata.
Ontvang ik de broncode?
Absoluut. Je ontvangt schone, goed gedocumenteerde en herbruikbare Python code, samen met uitleg over de workflow.