Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD
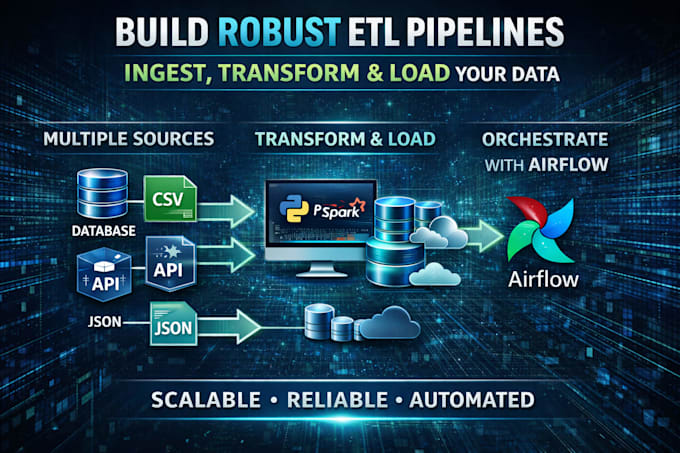
Data Engineer
Ik bied professionele ETL- en data engineering oplossingen om bedrijven te helpen hun data efficiënt te beheren en te analyseren.
Met mijn diensten krijg je:
Ik richt me op schaalbare, betrouwbare en goed gedocumenteerde oplossingen om je data klaar te maken voor analyse en besluitvorming.
Opmerking: Stuur me een bericht voordat je bestelt, zodat we je projectvereisten kunnen bespreken en de beste oplossing kunnen leveren.



Automatische vertaling
Q1: Ik ben nieuw in data engineering. Kun je me toch helpen?
A: Absoluut! Ik specialiseer me in het bouwen van ETL-pijplijnen en data warehouses voor alle bedrijfsgroottes, zelfs als je net begint.
Q2: Welke technologieën gebruik je?
A: Ik gebruik Python, PySpark, Airflow, PostgreSQL/MySQL, en kan dashboards integreren voor analytics.
Q3: Kan je meerdere databronnen integreren?
A: Ja! Ik kan data inladen uit CSV's, API's, databases en zelfs real-time streaming bronnen.
Q4: Lever je documentatie?
A: Ja. Elke pijplijn wordt geleverd met duidelijke documentatie en instructies voor eenvoudig onderhoud.
Q5: Kun je een data warehouse of star schema ontwerpen?
A: Zeker! Ik kan fact-dimension modellen en star schemas bouwen voor analytics en rapportages.
Q6: Bied je implementatieondersteuning aan?
A: Ja. Ik kan helpen bij het implementeren van pijplijnen lokaal, op een server of in cloud databases.
Q7: Hoe begin ik?
A: Stuur me een bericht met je projectvereisten voordat je bestelt. Ik geef een op maat gemaakt plan en tijdlijn.
Q8: Zijn je pijplijnen schaalbaar en betrouwbaar?
A: Absoluut. Ik bouw pijplijnen die robuust, efficiënt en ontworpen zijn om groeiende datavolumes aan te kunnen.