Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD
Biotechnologieonderzoeker: Microbial Genomics en Bioinformatics
Welkom! Als PhD-onderzoeker in Biotechnologie & Microbiologie bied ik expertanalyse voor Microbial RNA-Seq data.
Ik doe niet alleen code uitvoeren; ik ben een gepubliceerde onderzoeker die de wetenschap achter jouw resultaten begrijpt. Mijn specialisatie is Differentiële genexpressie (DGE) en het identificeren van de belangrijkste up/down-gereguleerde genen voor jouw studie.
### Wat deze dienst biedt (RNA-Seq DGE)
Ik bied drie analyseniveaus aan op basis van mijn bewezen pipeline (FastQC, HISAT2, featureCounts, DESeq2). (Zie mijn FAQ hieronder over sampleaantallen!).
* Basis (De "Data"):
Ik voer de volledige pipeline uit tot Read Counts (Stap 04). Dit pakket is perfect voor onderzoekers die R/Python gebruiken en alleen de uiteindelijke Counts Matrix nodig hebben.
* Standaard (De "Analyse"):
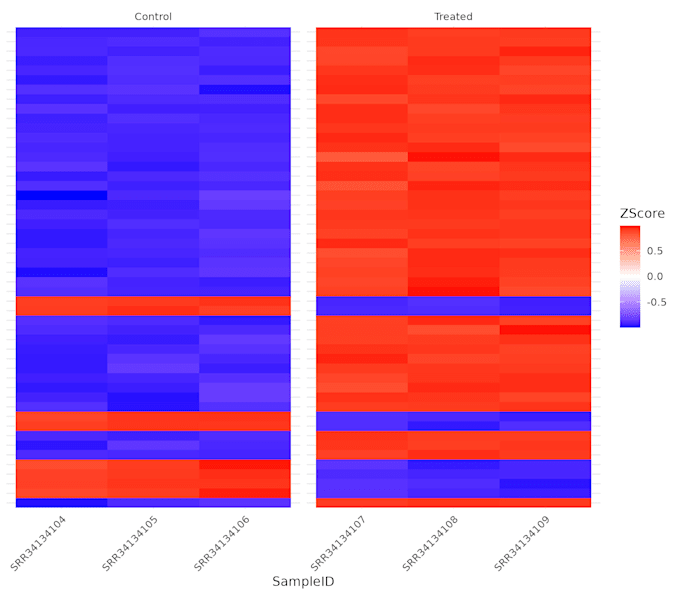
Dit is de volledige DGE Analyse (Stap 05). Je krijgt alles uit Basic, PLUS alle belangrijke visualisaties: Volcano Plot, PCA Plot en Heatmap.
* Premium (De "PhD Inzicht"):
Het volledige publicatieklare pakket. Je krijgt alles uit Standaard, PLUS: een volledig PDF-rapport met mijn deskundige Biologische Interpretatie (de "waarom") EN de reproduceerbare Jupyter Notebook die ik heb gebruikt voor jouw analyse.
**Neem contact met mij op voordat je bestelt om je project te bespreken.


_hmj74d.jpg)
Programmeertaal:
Python
•
R
•
SPSS
Technologie:
Jupyter Notebook
Expertise:
Clusteranalyse
Tools:
Pandas
Automatische vertaling
Je pakketprijzen vermelden niet het aantal samples. Waarom?
De pakketprijzen ($30, $50, $80) zijn een basis voor kleine pilotprojecten (bijvoorbeeld 1-3 samples). Voor grotere cohorten (4, 6 of 20+ samples), stuur me een bericht. We bespreken je doelen, en ik stuur je een nauwkeurige Custom Offer.
Waarom zou ik kiezen voor het Premium pakket? Wat is de waarde?
Premium is mijn PhD-niveau "Inzicht"-dienst. Ik bied niet alleen een lijst van genen; ik lever een uitgebreid PDF-rapport met <strong>Biologische Interpretatie</strong> (de "waarom"). Je krijgt ook de <strong>reproduceerbare Jupyter script</strong> voor je publicatie.
Wat heb je van mij nodig om te beginnen?
Ik heb 3 dingen nodig: 1. Je raw FASTQ-bestanden (R1 & R2). 2. Het referentiegenoom (FASTA) en annotatiebestanden (GFF/GTF). 3. Je metadata-bestand (bijvoorbeeld welke samples 'Control' vs 'Treated' zijn).