Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD
Laten we jouw project AFmaken
Welkom ;
Ik ben Big Data Engineer met 5 jaar ervaring,
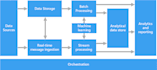
Ik kan je helpen bij het bouwen van je grote data project, inclusief data ingestion (met Apache Kafka), data opslag (in Hadoop of Amazon S3 of je externe Data Lake), data verwerking in batch of stream (real time) met pySpark of pyFlink, data analyse (met machine learning algoritmes en MLlib voor big data), en ook analyse en visualisatie in dashboard
Nou, mijn diensten omvatten:
100% geld terug garantie als het werk niet volgens de eisen wordt gedaan.
OPMERKING:
Op maat gemaakte opdrachten worden ook geaccepteerd. Stuur me een bericht voordat je bestelt.
Bedankt dat je hier bent. Stuur me nu een bericht om te beginnen.
Groeten,


Expertise:
Automatiseringen
•
Big data
•
etl
•
Transformatie
•
SQL
•
NoSQL
| (1) | ||
| (0) | ||
| (0) | ||
| (0) | ||
| (0) |
anushabandari
Terugkerende klant

Verenigde Staten
Good and very knowledgeable
| (1) | ||
| (0) | ||
| (0) | ||
| (0) | ||
| (0) |
anushabandari
Terugkerende klant
Verenigde Staten
Good and very knowledgeable


