Door categorieën bladeren
Ontdekken
Fiverr Pro
Nederlands
$
USD




Automatische vertaling
Heb je een dataset en heb je een werkend ML-model nodig dat
je daadwerkelijke probleem oplost?
Ik bouw, train en zet machine learning modellen in die zijn afgestemd op
jouw data en doel.
WAT IK BOUW:
- Classificatie (spam, fraude, churn, sentiment, afbeelding)
- Regressie & voorspelling (prijs, vraag, forecasting)
- Aanbevelingssystemen (collaborative filtering, SVD, NMF)
- NLP (sentimentanalyse, tekstclassificatie)
- Computer vision (afbeeldingsclassificatie, CNN)
GELIEVE & GEÏNTEGREERD:
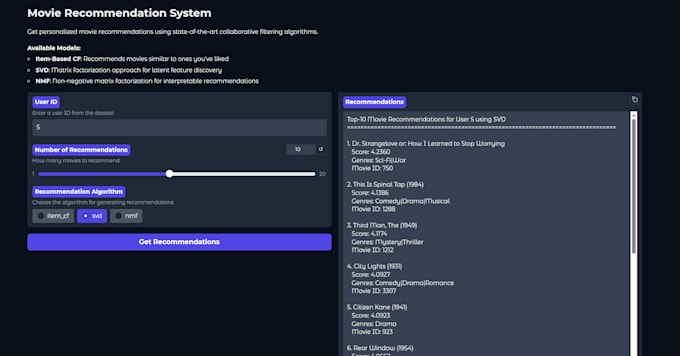
- Live aanbevelingssysteem voor films op Hugging Face
- Afbeeldingsclassificatie voor kat vs hond met 96% nauwkeurigheid, live op Hugging Face
- Sentimentclassificatie voor game reviews met 82% nauwkeurigheid
WAT JE KRIJGT:
- Getraind model met volledige evaluatiemetrics
- Schone Jupyter notebook met volledige pipeline
- GitHub repository met gedocumenteerde code
- Deployment op Hugging Face (Standaard & Premium)
STACK:
Python, scikit-learn, TensorFlow, Keras, NLTK,
Pandas, Gradio, Hugging Face, PyTorch
BELANGRIJK:
De klant moet de dataset aanleveren. Bestellingen kunnen niet
beginnen zonder data.
Full Stack Developer, AI, ML and Data Analytics
Talen
Automatische vertaling
Automatische vertaling
Wat heb je van mij nodig om te beginnen?
Jouw dataset (CSV, Excel of database export) en een duidelijke beschrijving van wat je wilt voorspellen of classificeren. Als je geen dataset hebt, stuur me eerst een bericht.
Wat als mijn dataset rommelig is of ontbrekende waarden heeft?
Basis data cleaning en preprocessing is inbegrepen in alle pakketten. Voor sterk ongestructureerde of grote datasets, neem eerst contact op om de scope te beoordelen.
Kan ik het model opnieuw trainen met nieuwe data?
Ja. De geleverde notebook bevat de volledige pipeline zodat je opnieuw kunt trainen met bijgewerkte data. Premium bevat documentatie over hoe je dit doet.
Welke nauwkeurigheid kan ik verwachten?
Hangt volledig af van de kwaliteit van je data en het type probleem. Ik rapporteer alle standaard metrics (accuracy, F1, precisie, recall, ROC-AUC) en ben transparant over de beperkingen van het model.
Kun je het model deployen zodat anderen het kunnen gebruiken?
Ja — Standaard en Premium omvatten deployment op Hugging Face met een Gradio interface. Premium bevat ook een API endpoint voor integratie in andere applicaties.
Werk je met afbeelding-, tekst- of tabelgegevens?
Alle drie. Computer vision (CNN), NLP (tekstclassificatie, sentiment), en gestructureerde tabelgegevens (classificatie, regressie, clustering).